XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (698 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

Recursion: Summary
By now the principle should be clear. Whenever you need to find something out by processing a sequence of items, write a recursive template that is given the sequence as a parameter. If the sequence isn't empty, deal with the first item, and make a recursive call to deal with the rest of the sequence that follows the first item.
As I mentioned, with XSLT 1.0 there was another problem when doing this, which had nothing to do with the lack of an assignment statement, but was a consequence of the limited range of types available. The result of a template in XSLT 1.0 was always a temporary tree, and with XSLT 1.0 (without the widely implemented
exslt:node-set()
extension) there were only two things you could do with the tree: you could copy it to the final result tree, or you could convert it to a string.
With XSLT 2.0, this becomes much easier because a template (or a function) can return an arbitrary sequence, which you can manipulate in any way you like. You can also choose to construct a temporary tree, which can now be manipulated just like an original source document. Furthermore, you can take advantage of the fact that in XSLT 2.0 a template rule or function can return references to existing nodes, by using the
For another example that takes advantage of this, see the Knight's Tour in Chapter 20.
Summary
This chapter described four design patterns for writing XSLT stylesheets:
- Fill-in-the-blanks
- Navigational
- Rule-based
- Computational
The approach to problems in the computational stylesheets may seem unfamiliar, because XSLT is a pure functional programming language, with no assignment statements or other side effects that constrain the order of execution. The result of this is that many of the more complex algorithms need to be written using recursive functions or templates.
Chapter 18
Case Study: XMLSpec
This is the first of a group of three chapters that aim to show how all the facilities of the XSLT language can work together to solve real XML processing problems of significant complexity. Most of the code is presented in these chapters, but the complete stylesheets, and specimen data files, can be downloaded from the Wrox Web site at
http://www.wrox.com/
.
As I described in the previous chapter, XSLT has a broad range of applications, and in these three chapters I have tried to cover a representative selection of problems. The three examples I have chosen are as follows:
- The first example is a stylesheet for rendering sequential documents: specifically, the stylesheet used for rendering W3C specifications such as the XML and XSLT Recommendations. This is a classic example of the
rule-based
design pattern described on page 980 in Chapter 17. - The second example, in Chapter 19, is concerned with presenting structured data. I chose a complex data structure with many cross-references to illustrate how a navigational stylesheet can find its way around the source tree: the chosen example is a data file containing the family tree of the Kennedys. This example is particularly suitable for demonstrating how stylesheets and schemas can work together.
- The final example stylesheet, in Chapter 20, is quite unrealistic but fun. It shows how XSLT can be used to calculate a knight's tour of the chessboard, in which the knight visits every square without ever landing on the same square twice. This is not the sort of problem XSLT was designed to solve, but by showing that it can be done I hope it will convince you that XSLT has the computational power and flexibility to deal with the many more modest algorithmic challenges that arise in routine day-to-day formatting applications. New features in XSLT 2.0 make this kind of application much easier to write, which means that the stylesheet is almost a total rewrite of the XSLT 1.0 version.
The stylesheet presented in this chapter was written for a practical purpose, not to serve as an example of good programming practice. I wrote in an earlier edition of this book that the stylesheet was originally written by Eduardo Gutentag and subsequently modified by James Clark. The stylesheet at that time was around 750 lines long. The current version has grown to over 3000 lines in three different stylesheet modules, and claims as its authors Norman Walsh, Chris Maden, Ben Trafford, Eve Maler, and Henry S. Thompson. No doubt others have contributed too, and I am grateful to W3C and to these individuals for placing the stylesheet in the public domain. Because the stylesheet has grown so much, and because many of the template rules are quite repetitive, I have omitted much of the detail from this chapter, selecting only those rules where there is something useful to say. But I haven't tried to polish the code for publication—I am presenting the stylesheet as it actually is, warts and all, because this provides many opportunities to discuss the realities of XSLT programming. It gives the opportunity to analyze the code as written and to consider possible ways in which it can be improved. To the individuals whose code I am criticizing, I apologize if this causes them any embarrassment. I do it because I know that all good software engineers value criticism, and these people are all top-class software engineers.
Before embarking on this chapter, I did wonder whether there was any value in presenting in a book about XSLT 2.0 a stylesheet that is written almost entirely using XSLT 1.0. As the chapter progressed, I found that it actually provided a good opportunity to identify those places where XSLT 2.0 can simplify the code that needs to be written. I hope that it will therefore serve not only as a case study in the use of XSLT 1.0 but also as an introduction to the opportunities offered by the new features in 2.0.
Formatting the XML Specification
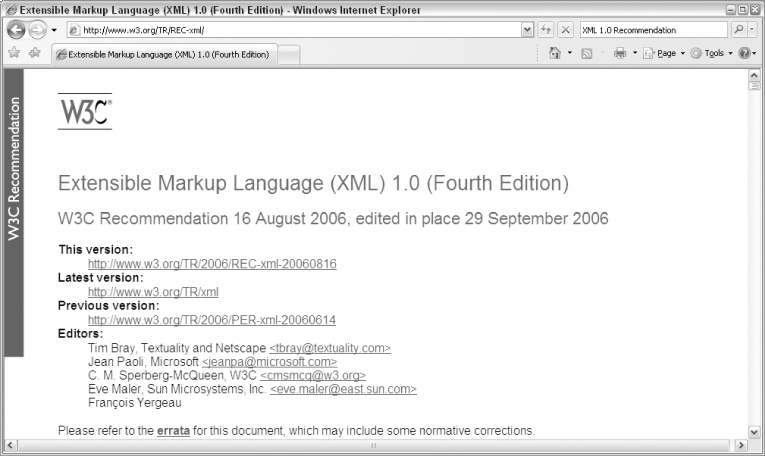
In this worked example, we'll study the stylesheet used for formatting the XML specifications themselves. You may have noticed that on the W3C Web site, you can get the specifications for standards such as XML, XSLT, and XPath either in XML format or in HTML. We'll look at a stylesheet for converting the XML Recommendation from its XML form to its HTML form, shown in
Figure 18-1
.
The DTDs and stylesheets used for the XSLT, XQuery, and XPath specifications are adapted from the version used for the XML specification, and we'll take a look at the adaptations too.
The download file for this chapter on
http://www.wrox.com/
contains the versions of the stylesheet modules that were actually used to publish the final XSLT 2.0 Recommendation on January 23, 2007. These may differ slightly from the version presented in the text.
This stylesheet is a classic example of the
rule-based
design pattern, which was introduced on page 980 in Chapter 17. It makes minimal assumptions about where all the different elements in the XML source document appear relative to each other, and it allows new rules to be added freely as the document structure evolves.
You'll probably find it helpful while reading this stylesheet to have the XML source document readily accessible. The official version of XML 1.0 Fourth Edition (the document shown above) is located on the Web at
http://www.w3.org/TR/REC-xml/REC-xml-20060816.xml
.
There is also a DTD called
xmlspec.dtd
. You can view the source either in a text editor or in an XML editor, such as XML Spy, or by using the default XML viewer in Internet Explorer or Firefox. Because there is an
reference to an XSLT stylesheet (specifically, the stylesheet presented in this chapter), the browser will automatically apply the stylesheet and show you the generated HTML.
You might imagine that XML parsers these days are pretty reliable, and that XML published by W3C is likely to be problem-free. However, I get an error trying to display this XML in Internet Explorer. It chokes on the DTD, with the message “
The character ‘>’ was expected. Error processing resource
http://www.w3.org/TR/REC-xml/xmlspec.dtd
. Line 218, Position 53”, showing a sample of text that suggests some kind of buffer corruption. The local copy of the document, which is included in the download file for this book, is supposedly identical, but displays in IE without problems. Well, almost without problems. On my configuration, to get the non-ASCII characters to display correctly, I have to change the stylesheet to say
There's another separate problem with the XML (also in the DTD) that causes the Microsoft .NET parser to reject it. You can see this problem if you try to apply the stylesheets using Saxon on .NET. This time the message is: “‘
xlink’ is an undeclared namespace. Line 380, position 9
.” The element in question is a
element, and there's no sign of an xlink namespace anywhere nearby. The DTD, however, adds attributes in the XLink namespace to a number of elements, and also attempts to declare the namespace at the same time. Since the DTD in this area is littered with comments saying “compensate for IE bug”, it looks as if the authors have stretched the use of advanced DTD features to the point where it breaks widely used XML parsers. The lesson seems to be: keep things simple.
If you want to avoid these problems, just delete the text SYSTEM “xmlspec.dtd”
SYSTEM “xmlspec.dtd” from the second line of the XML document.
from the second line of the XML document.
As often happens in publishing organizations, the W3C has struggled with the problem of improving its processes while also retaining backwards compatibility and a recognizable house style. It also has the classic conflict between the desire of the organization to maintain consistency of approach and the desire of editors to experiment and innovate. The stylesheet we are looking at was used to produce the fourth edition of the XML 1.0 specification, over 8 years after the original, and in that time it has been adapted to be able to handle many other specifications as well. Some of these changes have found their way into the original stylesheets, and some have resulted in “forking” of the code, as we will see when we look at the versions used to produce the XSLT specification.
The stylesheet used to publish XML 1.0 Fourth Edition consists of three modules:
REC-xml.xsl
, which imports
diffspec.xsl
, which imports
xmlspec.xsl
., as shown in
Figure 18-2
. While the role of
diffspec.xsl
is clearly to enable highlighting of changes between document versions, the functional split between the first and third of these modules is less clear. However, most of the work is done in
xmlspec.xsl
, and it is on this module that we shall focus our attention.

Preface
Let's start at the beginning:
The stylesheet is an XML document, so it starts with an XML declaration. There's no encoding declaration; actually, all the characters are ASCII, which means that any XML parser should be able to load this document without difficulty.
The comment is rather interesting. Earlier versions of the spec were published in HTML, not in XHTML. It's not easy to maintain two versions of a stylesheet, one to generate HTML and one for XHTML, because all the result elements are in different namespaces in the two cases. It seems that the production team solved this problem by writing a stylesheet that generated the XHTML stylesheet from the HTML version, by changing namespaces where necessary. As I have remarked elsewhere in this book, stylesheets that modify stylesheets seem to crop up very often in real-world XSLT-based applications.
The conversion means that the XHTML namespace is present on many elements in the stylesheet, but I've left it out in presenting the code because it adds a lot of clutter.
xmlns:saxon=“http://icl.com/saxon”
exclude-result-prefixes=“saxon”
version=“1.0”>