XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (695 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

temp = x;
x = y;
y = temp;
then the effect depends on executing them in the right order.
This means, of course, that a pure function can't update external variables. As soon as we allow assignment, we become dependent on doing things in sequence, one step at a time in the right order.
Don't object-oriented languages achieve the same thing by preventing one object from updating data held in another? No, because although they prevent direct writing to private data, they allow the same effect to be achieved by
get()
and
set()
methods. An update to a variable achieved indirectly through a defined interface creates exactly the same dependence on sequence of execution as an update done directly with an assignment statement. A pure function must have no side effects; its only output is the result it returns.
The main reason that functional languages are considered ideal for a stylesheet language (or a tree transformation language, if you prefer) is not so much the ability to do things in parallel or in any order, but rather the ability to do them incrementally. We want to get away from static pages; if you're showing a map of the traffic congestion hotspots in your area, then when the data for a particular road junction changes, you want the map updated in real time, and it should be possible to do this without recalculating and redrawing the whole map. This is only possible if there's a direct relationship—a function—between what's shown at a particular place on the map display and a particular data item in the underlying database. So if we can decompose our top-level stylesheet function,
O=S(I)
, into a set of smaller, independent functions, each relating one piece of the output to one piece of the input, then we have the potential to do this on-the-fly updating.
Another benefit of this incremental approach is that when a large page of XML is downloaded from the network, the browser can start displaying parts of the output as soon as the relevant parts of the input are available. Some XSLT processors already do this: Xalan, for example, runs the transformation in parallel with the XML parsing process. If the stylesheet were a conventional program with side effects, this wouldn't be possible, because the last bit of input to arrive could change everything.
The actual “functions” in XSLT take several forms. The most obvious functions in XSLT 2.0 are the stylesheet functions written using an
XSLT template rules and stylesheet functions act as small, independent functions relating one piece of the output to one piece of the input. Functions and template rules in XSLT have no side effects; their output is a pure function of their input. Stylesheet functions follow this model more strictly than templates, because the only input they have is the values of the parameters to the function (plus global variables and the results of functions such as
document()
, which access parts of the context that cannot vary from one function call to another within a given transformation). Templates are less pure, because they also take the current position in the input document, and other context information, as implicit input parameters. But the principle is the same.
Technically, functions in XSLT are not completely pure, because they can create nodes with distinct identity. If a function creates and returns a new node
, then calling the function twice with the same arguments produces two elements with the same content but with different identity, which means that the expression f() is f()
f() is f()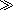 will return
will return
false
. Fortunately, it's not too difficult for an optimizer to detect when a function has this characteristic.
It doesn't matter in what order the template rules are executed, so long as we assemble their individual outputs together in the right way to form the result tree. If part of the input changes, then we need to reevaluate only those template rules that depend on that part of the input, slotting their outputs into the appropriate place in the output tree. In practice, of course, it's not as easy as that, and no one has yet implemented an incremental stylesheet processor that works like this. However, many XSLT processors do take advantage of the freedom to change the order of evaluation, by using a technique known as
lazy evaluation
.
Lazy evaluation means, in general, that expressions are not evaluated until their values are actually needed. This provides two benefits: firstly, it avoids allocating memory to hold the results. (Although modern machines have vast amounts of memory, processing large XSLT documents can be very memory-intensive, and the overhead of allocating and deallocating memory dynamically accounts for a lot of the cost of XSLT processing.) Secondly, lazy evaluation sometimes means that an expression doesn't need to be evaluated at all. To take a simple example, in a function call such as string-join($sequence, $separator)
string-join($sequence, $separator) , there is no need to evaluate the second argument unless the first argument is a sequence containing two or more items.
, there is no need to evaluate the second argument unless the first argument is a sequence containing two or more items.
Meanwhile, while the researchers and product developers work out how to optimize XSLT execution using incremental and parallel evaluation, you, as a user, are left with a different problem: learning how to program without assignment statements. After this rather lengthy digression into computer science theory, in the next section I shall get my feet back on the ground and show you some examples of how to do this.
However, first let's try and separate this from another programming challenge that arose with XSLT 1.0, namely the limited number of types available. This restriction has been greatly eased in XSLT 2.0, now that arbitrary sequences are available in the data model. In terms of language design principles, the lack of assignment statements and the absence of a rich type system are quite separate matters. With XSLT 1.0, you often hit the two issues together:
- The only effect a template could have was via the output it produced (because of the ban on side effects).
- And the only output it could produce, if you wanted to process it further, was a character string (because of the limited range of types available).
However, in XSLT 2.0 it becomes possible for a template to construct an arbitrary sequence or a tree, which can be used as input to further stages of processing. It is also possible for a template to return references to existing nodes in the source tree, without making a new copy. The introduction of temporary trees and sequences in XSLT 2.0 greatly reduces the contortions that are necessary to implement complex algorithms in your transformations.
So Why Are They Called Variables?
XSLT, as we have seen, does have variables that can hold values. You can initialize a variable to a value, but what you can't do is change the value of an existing variable once it has been initialized.
People sometimes ask, why call it a variable if you can't vary it? The answer lies in the traditional mathematical use of the word
variable
: a variable is a symbol that can be used to denote different values on different occasions. When I say “area = length × breadth,” then
area
,
length
, and
breadth
are names or symbols used to denote values: here, they denote properties of a rectangle. They are variables because these values are different every time I apply the formula, not because a given rectangle is changing size as I watch.
Avoiding Assignment Statements
In the following sections I'll look at some of the common situations where assignment statements appear to be needed, and show how to achieve the required effect without them.
Conditional Initialization
This problem has an easy solution, so I shall get it out of the way quickly.
In conventional languages you might want to initialize a variable to zero in some circumstances and to a value of one in others. You might write:
int x;
if (zeroBased) {
x=0;
} else {
x=1;
}
How can you do the equivalent in XSLT without an assignment statement? The answer is simple. Think of the equivalent:
int x = (zeroBased ? 0 : 1 );
which has its parallel in XSLT 2.0 as:
Another useful expression when initializing variables is:
which selects the value of the
discount
attribute if there is one, or zero otherwise.
Neither of these constructs was available in XSLT 1.0.
Avoid Doing Two Things at Once
Another common requirement for variables arises when you are trying to do two things at once. For example, you are trying to copy text to the output destination, and at the same time to keep a note of how much text you have copied. You might feel that the natural way of doing this is to keep the running total in a variable and update it as a side effect of the template that does the copying. Similarly, you might want to maintain a counter as you output nodes, so that you can start a new table row after every ten nodes.
Or perhaps you want to scan a set of numbers calculating both the minimum and the maximum value; or while outputting a list of employees, to set a flag for later use if any salary greater than $100,000 was found.
You have to think differently about these problems in XSLT. Think about each part of the output you want to produce separately and write a function (or template rule) that generates this piece of the output from the input data it needs. Don't think about calculating other things at the same time.
So you need to write one function to produce the output and another to calculate the total. Write one template to find the minimum and another to find the maximum.