Incognito (5 page)
Authors: David Eagleman


Change blindness.
What is the difference between them? Difficult to tell, isn’t it? In a dynamic version of this test, the two images are alternated (say, each image shown for half a second, with a tenth of a second blank period in between). And it turns out we are blind to shockingly large changes in the scene. A large box might be present in
one photo and not the other, or a jeep, or an airplane engine—and the difference goes unseen. Our attention slowly crawls the scene, analyzing interesting landmarks until it finally detects what is changing.
**
Once the brain has latched onto the appropriate object, the change is easy to see—but this happens only after exhaustive inspection. This “change blindness” highlights the importance of attention: to see an object change, you must attend to it.
5
You are not seeing the world in the rich detail that you implicitly believed you were; in fact, you are not aware of most of what hits your eyes. Imagine you’re watching a short film with a single actor in it. He is cooking an omelet. The camera cuts to a different angle as the actor continues his cooking. Surely you would notice if the actor changed into a different
person
, right? Two-thirds of observers don’t.
6
In one astonishing demonstration of change blindness, random pedestrians in a courtyard were stopped by an experimenter and asked for directions. At some point, as the unsuspecting subject was in the middle of explaining the directions, workmen carrying a door walked rudely right between the two people. Unbeknownst to the subject, the experimenter was stealthily replaced by a confederate who had been hiding behind the door as it was carried: after the door passed, a new person was standing there. The majority of subjects continued giving directions without noticing that the person was not the same as the original one they were talking with.
7
In other words, they were only encoding small amounts of the information hitting their eyes. The rest was assumption.
Neuroscientists weren’t the first to discover that placing your eyes on something is no guarantee of seeing it. Magicians figured this out long ago, and perfected ways of leveraging this knowledge.
8
By directing your attention, magicians perform sleight of hand in full view. Their actions
should
give away the game—but they can
rest assured that your brain processes only small bits of the visual scene, not everything that hits your retinas.
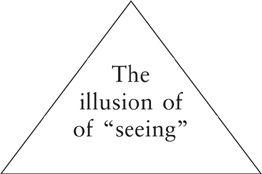
This fact helps to explain the colossal number of traffic accidents in which drivers hit pedestrians in plain view, collide with cars directly in front of them, and even intersect unluckily with trains. In many of these cases, the eyes are in the right place, but the brain isn’t seeing the stimuli. Vision is more than looking. This also explains why you probably missed the fact that the word “of” is printed twice in the triangle above.
The lessons here are simple, but they are not obvious, even to brain scientists. For decades, vision researchers barked up the wrong tree by trying to figure out how the visual brain reconstructed a full three-dimensional representation of the outside world. Only slowly did it become clear that the brain doesn’t actually use a 3-D model—instead, it builds up something like a 2½-D
sketch
at best.
9
The brain doesn’t need a full model of the world because it merely needs to figure out, on the fly, where to look, and when.
10
For example, your brain doesn’t need to encode all the details of the coffee shop you’re in; it only needs to know how and where to search when it wants something in particular. Your internal model has some general idea that you’re in a coffee shop, that there are people to your left, a wall to your right, and that there are several items on the table. When your partner asks, “How many lumps of sugar are left?” your attentional systems interrogate the details of the bowl, assimilating new data into your internal model. Even though the sugar bowl has been in your visual field the entire time, there was no real detail there for your brain. It needed to do extra work to fill in the finer points of the picture.
Similarly, we often know one feature about a stimulus while simultaneously being unable to answer others. Say I were to ask you to look at the following and tell me what it is composed of: ||||||||||||. You would correctly tell me it is composed of vertical lines. If I were to ask you
how many
lines, however, you would be stuck for a while. You can see
that
there are lines, but you cannot tell me
how many
without considerable effort. You can know some things about
a scene without knowing other aspects of it, and you become aware of what you’re missing only when you’re asked the question.
What is the position of your tongue in your mouth? Once you are asked the question you can answer it—but presumably you were not aware of the answer until you asked yourself. The brain generally does not need to know most things; it merely knows how to go out and retrieve the data. It computes on a
need-to-know basis
. You do not continuously track the position of your tongue in consciousness, because that knowledge is useful only in rare circumstances.
In fact, we are not conscious of much of anything until we ask ourselves about it. What does your left shoe feel like on your foot right now? What pitch is the hum of the air conditioner in the background? As we saw with
change blindness, we are unaware of most of what should be obvious to our senses; it is only after deploying our attentional resources onto small bits of the scene that we become aware of what we were missing. Before we engage our concentration, we are typically not aware that we are not aware of those details. So not only is our perception of the world a construction that does not accurately represent the outside, but we additionally have the false impression of a full, rich picture when in fact we see only what we need to know, and no more.
The manner in which the brain interrogates the world to gather more details was investigated in 1967 by the Russian psychologist
Alfred Yarbus. He measured the exact locations that people were looking at by using an eye tracker, and asked his subjects to gaze at
Ilya Repin’s painting
An Unexpected Visitor
(below).
11
The subjects’ task was simple: examine the painting. Or, in a different condition, surmise what the people in the painting had been doing just before the “unexpected visitor” came in. Or answer a question about how wealthy the people were. Or their ages. Or how long the unexpected visitor had been away.

Six records of eye movements from the same subject. Each record lasted three minutes.

1) Free examination. Before subsequent recordings, the subject was asked to: 2) estimate the material circumstances of the family;

3) give the ages of the people; 4) surmise what the family had been doing before the arrival of the “unexpected visitor”;

5) remember the clothes worn by the people; 6) estimate how long the “unexpected visitor” had been away from the family. From Yarbus, 1967.
The results were remarkable. Depending on what was being asked, the eyes moved in totally different patterns, sampling the picture in a manner that was maximally informative for the question at
hand. When asked about the ages of the people, the eyes went to the faces. When asked about their wealth, the focus danced around the clothes and material possessions.
Think about what this means: brains reach out into the world and actively
extract
the type of information they need. The brain does not need to see everything at once about
An Unexpected Visitor
, and it does not need to store everything internally; it only needs to know where to go to find the information. As your eyes interrogate the world, they are like agents on a mission, optimizing their strategy for the data. Even though they are “your” eyes, you have little idea what duty they’re on. Like a black ops mission, the eyes operate below the radar, too fast for your clunky consciousness to keep up with.