In Pursuit of the Unknown (20 page)
Read In Pursuit of the Unknown Online
Authors: Ian Stewart

Now I'll explain how this clever structure makes the proof work.
Figure 21
shows the key stages. Take your solid. Deform it into a nice round sphere, with its edges being curves on that sphere. If two faces meet along a common edge, then you can remove that edge and merge the faces into one. Since this merger reduces both
F
and
E
by 1, it doesn't change
F
â
E
+
V
. Keep doing this until you get down to a single face, which covers almost all of the sphere. Aside from this face, you are left with only edges and vertices. These must form a tree, a network with no closed loops, because any closed loop on a sphere separates at least two faces: one inside it, the other outside it. The branches of this tree are the remaining edges of the solid, and they join together at the remaining vertices. At this stage only one face remains: the entire sphere, minus the tree. Some branches of this
tree connect to other branches at both ends, but some, at the extremes, terminate in a vertex, to which no other branches attach. If you remove one of these terminating branches together with that vertex, then the tree gets smaller, but since both
E
and
V
decrease by 1,
F
â
E
+
V
again remains unchanged.
This process continues until you are left with a single vertex sitting on an otherwise featureless sphere. Now
V
=1,
E
=0, and
F
=1. So
F
â
E
+
V
= 1â0 + 1 = 2. But since each step leaves
F
â
E
+
V
unchanged, its value at the beginning must also have been 2, which is what we want to prove.

Fig 21
Key stages in simplifying a solid.
Left to right
: (1) Start. (2) Merging adjacent faces. (3) Tree that remains when all faces have been merged. (4) Removing an edge and a vertex from the tree. (5) End.
It's a cunning idea, and it contains the germ of a far-reaching principle. The proof has two ingredients. One is a simplification process: remove either a face and an adjacent edge or a vertex and an edge that meets it. The other is an invariant, a mathematical expression that remains unchanged whenever you carry out a step in the simplification process. Whenever these two ingredients coexist, you can compute the value of the invariant for any initial object by simplifying it as far as you can, and then computing the value of the invariant for this simplified version. Because it is an invariant, the two values must be equal. Because the end result is simple, the invariant is easy to calculate.
Now I have to admit that I've been keeping one technical issue up my sleeve. Descartes's formula does not, in fact, apply to any solid. The most familiar solid for which it fails is a picture frame. Think of a picture frame made from four lengths of wood, each rectangular in cross-section, joined at the four corners by 45° mitres as in
Figure 22
(
left
). Each length of wood contributes 4 faces, so
F
=16. Each length also contributes 4 edges, but the mitre joint creates 4 more at each corner, so
E
= 32. Each corner comprises 4 vertices, so
V
= 16. Therefore
F
â
E
+
V
= 0.
What went wrong?
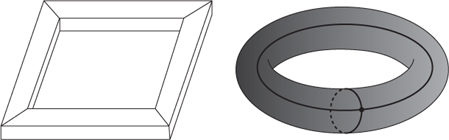
Fig 22
Left
: A picture frame with
F
â
E
+
V
= 0.
Right
: Final configuration when the picture frame is smoothed and then simplified.
There's no problem with
F
â
E
+
V
being invariant. Neither is there much of a problem with the simplification process. But if you work through it for the frame, always cancelling one face against one edge, or one vertex against one edge, then the final simplified configuration is not a single vertex sitting in a single face. Performing the cancellation in the most obvious way, what you get is
Figure 22
(
right
), with
F
= 1,
V
= 1,
E
= 2. I've smoothed the faces and edges for reasons that will quickly become apparent. At this stage removing an edge just merges the sole remaining face with itself, so the changes to the numbers no longer cancel. This is why we stop, but we're home and dry anyway: for this configuration,
F
â
E
+
V
= 0. So the
method
performs perfectly. It just yields a different result for the picture frame. There must be some fundamental difference between a picture frame and a cube, and the invariant
F
â
E
+
V
is picking it up.
The difference turns out to be a topological one. Early in my version of Euler's proof, I told you to take the solid and âdeform it into a nice round sphere'. But this is not possible for the picture frame. It's not shaped like a sphere, even after being simplified. It is a torus, which looks like an inflatable rubber ring with a hole through the middle. The hole is also clearly visible in the original shape: it's where the picture would go. A sphere, in contrast, has no holes. The hole in the frame is why the simplification process leads to a different result. However, we can wrest victory from the jaws of defeat, because
F
â
E
+
V
is still an invariant. So the proof tells us that
any
solid that is deformable into a torus will satisfy the slightly different equation
F
â
E
+
V
= 0. In consequence, we have the basis of a rigorous proof that a torus cannot be deformed into a sphere: that is, the two surfaces are topologically different.
Of course this is intuitively obvious, but now we can support intuition with logic. Just as Euclid started from obvious properties of points and lines, and formalised them into a rigorous theory of geometry, the
mathematicians of the nineteenth and twentieth centuries could now develop a rigorous formal theory of topology.

Fig 23
Left
: 2-holed torus.
Right
: 3-holed torus.
Where to start was a no-brainer. There exist solids like a torus but with two or more holes, as in
Figure 23
, and the same invariant should tell us something useful about those. It turns out that any solid deformable into a 2-holed torus satisfies
F
â
E
+
V
= â2, any solid deformable into a 3-holed torus satisfies
F
â
E
+
V
= â4, and in general any solid deformable into a
g
-holed torus satisfies
F
â
E
+
V
= 2â2
g
. The symbol
g
is short for âgenus', the technical name for ânumber of holes'. Pursuing the line of thought that Descartes and Euler began leads to a connection between a quantitative property of solids, the number of faces, vertices, and edges, and a qualitative property, possessing holes. We call
F
â
E
+
V
the Euler characteristic of the solid, and observe that it depends only on which solid we are considering and not on how we cut it into faces, edges, and vertices. This makes it an intrinsic feature of the solid itself.
Agreed, we count the number of holes, a quantitative operation, but âhole' itself is qualitative in the sense that it's not obviously a feature of the solid at all. Intuitively, it's a region in space where the solid
isn't
. But not any such region. After all, that description applies to all of the space surrounding the solid, and no one would consider it all to be a hole. And it also applies to all of the space surrounding a sphere . . . which doesn't
have
a hole. In fact, the more you start to think about what a hole is, the more you realise that it's quite tricky to define one. My favourite example to show just how confusing it all gets is the shape in
Figure 24
, known as a hole-through-a-hole-in-a-hole. Apparently you can thread a hole through another hole, which is actually a hole in a third hole.
This way lies madness.
It wouldn't much matter if solids with holes in them never turned up anywhere important. But by the end of the nineteenth century they were turning up all over mathematics â in complex analysis, algebraic geometry, and Riemann's differential geometry. Worse, higher-dimensional analogues of solids were taking centre stage, in all areas of pure and applied mathematics; as already noted, the dynamics of the Solar System requires 6 dimensions per body. And they had higher-dimensional analogues of holes. Somehow it was necessary to bring a modicum of order into the area. And the answer turned out to be . . . invariants.
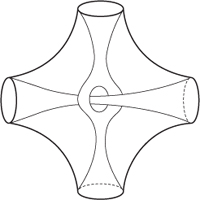
Fig 24
Hole-through-a-hole-in-a-hole.
The idea of a topological invariant goes back to Gauss's work on magnetism. He was interested in how magnetic and electrical field lines could link with each other, and he defined the linking number, which counts how many times one field line winds round another. This is a topological invariant: it remains the same if the curves are continuously deformed. He found a formula for this number using integral calculus, and every so often he expressed a wish for a better understanding of the âbasic geometric properties' of diagrams. It is no coincidence that the first serious inroads into such an understanding came through the work of one of Gauss's students, Johann Listing, and Gauss's assistant August Möbius. Listing's
Vorstudien zur Topologie
(âStudies in Topology') of 1847 introduced the word âtopology', and Möbius made the role of continuous transformations explicit.
Listing had a bright idea: seek generalisations of Euler's formula. The expression
F
â
E
+
V
is a combinatorial invariant: a feature of a specific way of describing a solid, based on cutting it into faces, edges, and vertices. The number
g
of holes is a topological invariant: something that does not change however the solid is deformed, as long as the deformation is continuous. A topological invariant captures a qualitative conceptual feature of a shape; a combinatorial one provides a method for calculating it. The two together are very powerful, because we can use the conceptual
invariant to think about shapes, and the combinatorial version to pin down what we are talking about.