XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (10 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

The XSLT stylesheet now takes this sequence of strings and applies the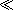 group-by=“.”
group-by=“.”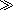 , which means that the values (the words) are grouped on their own value. (In another application, we might have chosen to group them by their length, or by their initial letter.) So, the body of the instruction is executed once for each distinct word, and the
, which means that the values (the words) are grouped on their own value. (In another application, we might have chosen to group them by their length, or by their initial letter.) So, the body of the instruction is executed once for each distinct word, and the
Don't worry if this example seemed a bit bewildering: it uses many concepts that haven't been explained yet. The purpose was to give you a feeling for some of the new features in XSLT 2.0 and XPath 2.0, which will all be explained in much greater detail elsewhere in this book.
Having dipped our toes briefly into some XSLT code, I'd now like to take a closer look at the relationship between XSLT and XPath and other XML-related technologies.
The Place of XSLT in the XML Family
XSLT is published by the World Wide Web Consortium (W3C) and fits into the XML family of standards, most of which are also developed by W3C. In this section I will try to explain the sometimes-confusing relationship of XSLT to other related standards and specifications.
XSLT and XSL Formatting Objects
XSLT started life as part of a bigger language called
XSL
(
Extensible Stylesheet Language
). As the name implies, XSL was (and is) intended to define the formatting and presentation of XML documents for display on screen, on paper, or in the spoken word. As the development of XSL proceeded, it became clear that this was usually a two-stage process: first a structural transformation, in which elements are selected, grouped and reordered; and then a formatting process in which the resulting elements are rendered as ink on paper, or pixels on the screen. It was recognized that these two stages were quite independent, so XSL was split into two parts: XSLT for defining transformations; and “the rest”—which is still officially called XSL, though most people prefer to call it
XSL-FO
(
XSL Formatting Objects
)—for the formatting stage.
XSL-FO is nothing more than another XML vocabulary, in which the objects described are areas of the printed page and their properties. Since this is just another XML vocabulary, XSLT needs no special capabilities to generate this as its output. XSL-FO is outside the scope of this book. It's a big subject. XSL-FO provides wonderful facilities to achieve high-quality typographical output of your documents. However, for many people translating documents into HTML for presentation by a standard browser is quite good enough, and that can be achieved using XSLT alone, or if necessary, by using XSLT in conjunction with Cascading Style Sheets (CSS or CSS2), which I shall return to shortly.
It's best to avoid the term XSL, because it's used with so many different meanings. It's the proper name for XSL Formatting Objects, but many people use it to mean XSLT. It's also used in older Microsoft documents to refer to their obsolete WD-xsl language, which was issued as part of Internet Explorer 4 before XSLT was standardized in 1999.
XSLT and XPath
Halfway through the development of XSLT 1.0, it was recognized that there was a significant overlap between the expression syntax in XSLT for selecting parts of a document and the XPointer language being developed for linking from one document to another. To avoid having two separate but overlapping expression languages, the two committees decided to join forces and define a single language,
XPath
, which would serve both purposes. XPath 1.0 was published on the same day as XSLT 1.0, November 16, 1999.
XPath acts as a sublanguage within an XSLT stylesheet. An XPath expression may be used for numerical calculations or string manipulations, or for testing Boolean conditions, but its most characteristic use (and the one that gives it its name) is to identify parts of the input document to be processed. For example, the following instruction outputs the average price of all the books in the input document:
Here, the
select
attribute contains an XPath expression, which calculates the value to be written: specifically, the average value of the
price
attributes on all the
avg()
function too is new in XPath 2.0.)
Following its publication, the XPath specification increasingly took on a life of its own, separate from XSLT. Several DOM implementations (including Microsoft's) allowed you to select nodes within a DOM tree structure, using a method such as
selectNodes(XPath)
, and this feature is now included in the current version of the standard, DOM3. Subsets of XPath are used within the XML Schema language and in XForms for defining validation conditions, and bindings of XPath to other languages such as Perl are multiplying. Perhaps most important of all, the designers of XQuery decided to make their language a pure superset of XPath. The language has also proved interesting to academics, and a number of papers have been published analyzing its semantics, which provides the basis for optimized implementations.
XSLT and XML Namespaces
XSLT is designed on the basis that
XML namespaces
are an essential part of the XML standard. So when the XSLT standard refers to an XML document, it always means an XML document that conforms to the XML Namespaces specification, which can be found at
http://www.w3.org/TR/REC-xml-names
.
Namespaces play an important role in XSLT. Their purpose is to allow you to mix tags from two different vocabularies in the same XML document. We've already seen how a stylesheet can mix elements from the target vocabulary (for example HTML or XSL-FO) with elements that act as XSLT instructions. Here's a quick reminder of how namespaces work:
- Namespaces are identified by a Uniform Resource Identifier (URI). This can take a number of forms. One form is the familiar URL, for example
http://www.wrox.com/namespace
. Another form, not fully standardized but being used in some XML vocabularies, is a URN, for example
urn:biztalk-org:biztalk:biztalk_1
. The detailed form of the URI doesn't matter, but it is a good idea to choose one that will be unique. One good way of achieving this is to use the domain name of your own website. But don't let this confuse you into thinking that there must be something on the website for the URI to point to. The namespace URI is simply a string that you have chosen to be different from other people's namespace URIs; it doesn't need to point to anything. - The latest version, XML Namespaces 1.1, allows you to use an International Resource Identifier (IRI) rather than a URI. The main difference is that this permits characters from any alphabet (for example, Chinese); it is no longer confined to ASCII. In practice, most XML parsers have always allowed you to use any characters you like in a namespace URI.
- Since namespace URIs are often rather long and use special characters such as
 /
/ , they are not used in full as part of the element and attribute names. Instead, each namespace used in a document can be given a short nickname, and this nickname is used as a prefix of the element and attribute names. It doesn't matter what prefix you choose, because the real name of the element or attribute is determined only by its namespace URI and its local name (the part of the name after the prefix). For example, all my examples use the prefix
, they are not used in full as part of the element and attribute names. Instead, each namespace used in a document can be given a short nickname, and this nickname is used as a prefix of the element and attribute names. It doesn't matter what prefix you choose, because the real name of the element or attribute is determined only by its namespace URI and its local name (the part of the name after the prefix). For example, all my examples use the prefix
xsl
to refer to the namespace URI
http://www.w3.org/1999/XSL/Transform
, but you could equally well use the prefix
xslt
, so long as you use it consistently. - For element names, you can also declare a default namespace URI, which is to be associated with unprefixed element names. The default namespace URI, however, does not apply to unprefixed attribute names.
A namespace prefix is declared using a special pseudo-attribute within any element start tag, with the form:
xmlns:prefix = “namespace-URI”
This declares a namespace prefix, which can be used for the name of that element, for its attributes, and for any element or attribute name contained in that element. The default namespace, which is used for elements having no prefix (but not for attributes), is similarly declared using a pseudo-attribute:
xmlns = “namespace-URI”
XML Namespaces 1.1 became a Recommendation on February 4, 2004, and the XSLT 2.0 specification makes provision for XSLT processors to work with this version, though it isn't required. Apart from the largely cosmetic change from URIs to IRIs mentioned earlier, the main innovation is the ability to undeclare a namespace, using syntax of the formxmlns:prefix=“”. This is particularly intended for applications like SOAP messaging, where an XML payload document is wrapped in an XML envelope for transmission. Without namespace undeclarations, there is a tendency for namespaces used in the SOAP envelope to stick to the payload XML when this is removed from the envelope, which can cause problems—for example, it can invalidate a digital signature attached to the document.