XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (803 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

The following example demonstrates the last of these techniques.
Example: Using saxon:evaluate() to Apply Business Rules
In this example, we imagine a call center that is charging customers for the calls they make. We want to prepare the account for a period, listing all the calls and calculating the total charge.
Source
The list of calls is in the file
calls.xml
, as follows:
We want to put the business rules for calculating the charges in a separate document. Of course, these rules could go in the stylesheet, but this isn't very good practice; mixing business rules and presentation rules in one place doesn't give the right separation of responsibilities. Instead, we'll put the relevant formula in a separate document
tariff.xml
, in the form of an XPath expression. This calculates the total charge, with different rates per minute during the working day and outside office hours:
sum(call[@time >= 08.00 and @time < 18.00]/@duration) * 1.50 +
sum(call[@time < 08.00 or @time >= 18.00]/@duration) * 2.50
Stylesheet
Most of the stylesheet (
account.xsl
) is conventional, and is concerned with displaying the information. When it comes to calculating the total charges, however, the stylesheet reads the XPath expression containing the relevant formula from the
tariff.xml
document and evaluates it (using
saxon:evaluate()
) in the context of the source document.
xmlns:saxon=“http://saxon.sf.net/”
version=“1.0”>
Account for period ending
select=“saxon:evaluate(document(‘tariff.xml’))”/>
Total charges for the period:
An observation on this stylesheet: This was first written to work with XSLT 1.0. In principle, it could be rewritten to use the facilities for arithmetic on dates, times, and durations provided in XSLT 2.0. However, little would be gained by doing so. Converting the application to use these facilities would require times to be written as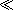 xs:time(‘08:00:00’)
xs:time(‘08:00:00’)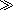 rather than as08.00, which would also create a dependency on the declaration of the namespace prefixxs. Also, multiplying a duration by a number in XPath 2.0 returns a duration, not a cost. Just because the facilities are provided doesn't mean that you have to use them, and in this case, it seems simpler not to.
rather than as08.00, which would also create a dependency on the declaration of the namespace prefixxs. Also, multiplying a duration by a number in XPath 2.0 returns a duration, not a cost. Just because the facilities are provided doesn't mean that you have to use them, and in this case, it seems simpler not to.
To run this stylesheet, make the directory containing the downloaded files for this chapter the current directory, and enter:
java -jar c:\saxon\saxon9.jar -s:calls.xml -xsl:account.xsl -o:bill.html
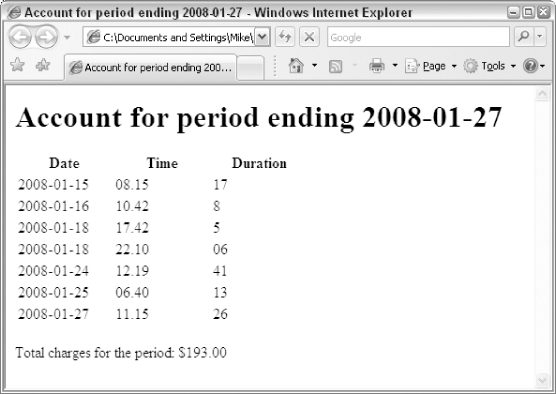
Output
The output of this stylesheet (bill.html) appears in the browser as shown in
Figure F-1
.
Summary
This appendix describes how to install and use the Saxon product, and how to invoke it from a Java or .NET application. It also describes some of the facilities provided by Saxon that go beyond the XSLT 2.0 specification itself.
Appendix G
Altova
Altova is the company that produces the popular XMLSpy toolkit. Among its many capabilities this includes an XSLT 2.0 processor, which can be used either as part of XMLSpy or on its own from the command line or via one of a number of application programming interfaces. XMLSpy is commercial software that can be purchased from
www.altova.com
.
Altova's XSLT 2.0 processor is available as a free (but not open source) download from the same site—it is part of a package called AltovaXML that also includes an XML validating parser, an XML Schema processor, an XQuery engine, and an XSLT 1.0 processor. The XQuery and XSLT 2.0 processors are both schema-aware. Although the product is internally a COM component, APIs are offered for COM, Java, and .NET.
As well as the XSLT 2.0 processor itself, XMLSpy also includes an interactive XSLT debugger and a profiler for performance analysis.
Both products run on Windows only. The version described in this chapter is the 2008 edition.
Running from within XMLSpy
An example showing how to run a simple “Hello World” stylesheet from within XMLSpy was given in Chapter 1 (see page 11).
Remember that XMLSpy includes both an XSLT 1.0 and an XSLT 2.0 processor, and the one it uses depends on the version
version attribute in yourversion=“1.0”.
attribute in yourversion=“1.0”.
When you click F10 (or the relevant icon or menu item) to fire off a transformation, the only thing you are asked for is the filename of the source document to be transformed. If you want to supply parameters to the transformation, there is a separate dialog box for this: select the menu item
XSL/XQuery
, then
XSL Parameters/XQuery Variables
. The value of the parameter is interpreted as an XPath expression, so if you want to supply a simple string, then it has to be in quotes.
There's no option to start the transformation without a source document, with a named template, or in a named mode; in fact, there are no other options at all. This also applies when the processor is launched from the command line or using the API. Instead, use the XSLT 1.0 technique of addingmatch=“/”to the entry template (remember that a template can have both a
match
attribute and a
name
attribute), and supply a dummy input document.
Using Tools ⇒ Options ⇒ XSL, you can configure XMLSpy to use a different transformation engine. You can either select MSXML (versions 3, 4, or 6), or you can connect to an external processor (for example, Saxon) by giving a template for its command line interface. This can be useful if you want to check that your stylesheets work with more than one processor, or if you want a second opinion when you get an error message that you don't understand. This feature also caters to people who want to use XMLSpy to develop stylesheets and then to use a different engine for live deployment.
Conformance
You may find suggestions on the web that the Altova processor is less than fully conformant with the W3 C Recommendations. However, the level of conformance has been steadily improving with each successive release, and the 2008 release has very few restrictions that are likely to affect the typical user. Most of the gaps that were present in the 2007 version have been plugged, for example
format-date()
is now fully supported, and
upper-case()
and
lower-case()
now work with the full Unicode character set. We've tested most of the examples in this book against both Saxon and Altova, and where we found a problem, we've pointed it out.
Altova supports all of the optional features of the XSLT 2.0 specification, including schema awareness, serialization, the namespace axis,
disable-output-escaping
, and backward compatibility. (Backward compatibility is not normally invoked when running inside XMLSpy, because XMLSpy chooses an XSLT 1.0 processor when you specifyversion=“1.0”. However, you can force the issue by importing an XSLT 1.0 stylesheet module into an XSLT 2.0 module, and it handles this correctly.)
One remaining area where Altova warns you about significant differences in behavior is in the area of whitespace handling. Like the Microsoft MSXML parser, the Altova XML parser strips whitespace text nodes from the source document before XSLT processing starts; unlike the Microsoft parser, there doesn't appear to be anything you can do to prevent this.
There are two problems this can cause:
- In the first case, you aren't actually interested in the boundary whitespace, so it doesn't matter that it has been removed, except that your stylesheet was written on the assumption that it was there, so it stops working. The best answer here is to add the declaration
- In other cases, the whitespace might really be meaningful. This happens most often with mixed content, that is, with narrative documents. If your document contains two adjacent bold words with a space between them, like this:
It was a long hard winter
then you don't want the space to disappear. Altova's only suggestion for dealing with this problem is to modify the source document, by moving the space character inside one of the two adjacent elements. (If you want to do this with XSLT, of course, you will need to use a processor that doesn't strip whitespace.…)
Extensions and Extensibility
As far as I have been able to determine, Altova includes no built-in extensions in its product, that is, no extra functions or top-level declarations in a vendor-defined namespace.
There also appear to be no facilities for creating user-defined extensions, that is, callouts to code written in languages such as Java and JavaScript.
The
doc()
and
document()
functions generally work as you would expect. Like many Microsoft products (but unlike Saxon), they generally interpret “URI” in the specifications to mean “URI or Windows filename”, so strings likec:\temp\data.xmlare accepted in places where a URI is expected. There's no ability to work with a user-supplied URI resolver or catalog to redirect URI references to local copies (if you need this, consider using the
collection()
function instead—see below).