XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (244 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

The exclude-result-prefixes Attribute
This attribute defines a set of namespaces that are
not
to be copied into the result tree.
The XSLT processor is required to produce a correct tree that conforms with the XDM data model (as described on page 45, in Chapter 2) and with the XML Namespaces rules, so you will never find yourself with an output file using namespace prefixes that have not been declared. However, you can easily find yourself with a file containing unnecessary and unwanted namespace declarations; for example, declarations of namespaces that occur on nodes in your source document but are not used in the output document, or namespaces for extension functions that are used only in the stylesheet. These extra namespace declarations usually don't matter, because they don't affect the meaning of the output file, but they can clutter it up. They can also affect validation if you are trying to create a result document that conforms to a particular DTD. So this attribute is provided to help you get rid of them.
Effect
The XSLT specification requires that when a literal result element in the stylesheet is evaluated, the element is copied into the result tree along with all its namespace nodes, except for the XSLT namespace and any namespace that defines extension instructions. An element has a namespace node for every namespace that is in scope, including namespaces defined on ancestor elements as well as on the element itself, so the namespaces copied over include not only the namespaces defined on the literal result element, and those that are actually used on the literal result element, but even those that are merely
available
for use.
Very often, of course, one literal result element will be a child or descendant of another, and the namespace nodes on the child element will include copies of all the namespace nodes on the parent element. For example, consider the stylesheet below:
xmlns:xsl=“http://www.w3.org/1999/XSL/Transform”/>
Once upon a time …
This is represented by the tree shown in
Figure 6-12
, using the same notation as previously seen in Chapters 2 and 3. Although there are only two namespace declarations, these are propagated to all the descendant elements, so for example the xml
xml namespace, which is not shown in
namespace, which is not shown in
Figure 6-12
.)
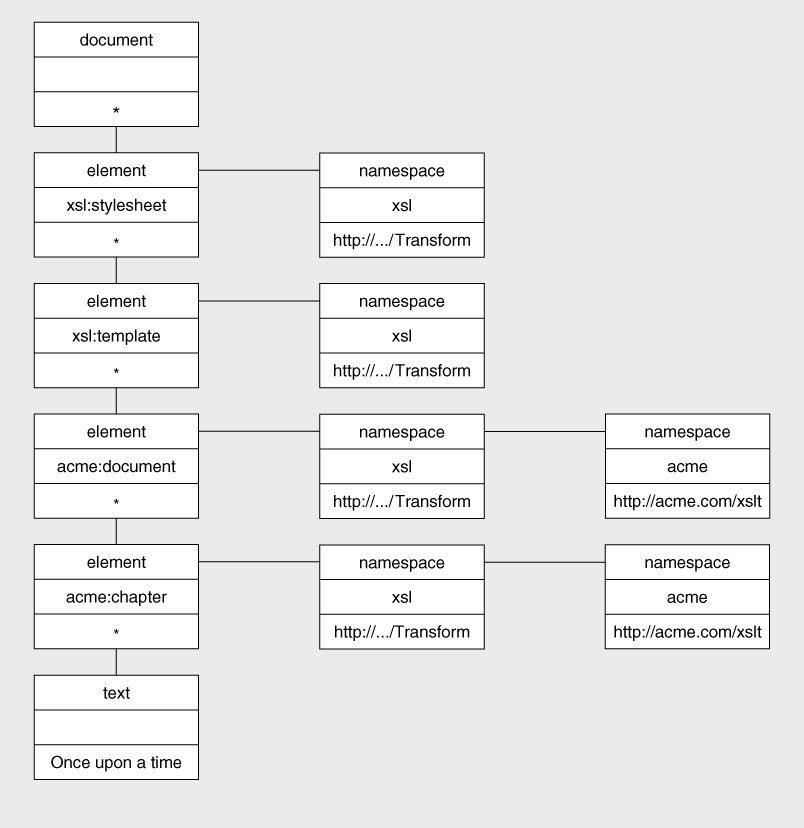
The specification says that each literal result element is copied with all its namespace nodes (but excluding the XSLT namespace), so the result tree will resemble
Figure 6-13
(again, thexmlnamespace nodes are omitted).
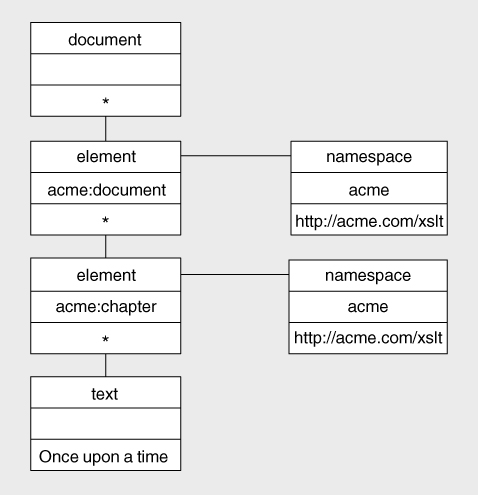
Both elements,acmenamespace. However, this doesn't mean that the namespace declaration will be repeated unnecessarily in the output file: we're talking here about the abstract tree that is created, not the final serialized XML file. Avoiding duplicate namespace declarations is entirely the job of the XSLT serializer, and most serializers will produce the following output, shown indented for clarity:
Once upon a time …
What exclude-result-prefixes Does
The
exclude-result-prefixes
attribute isn't present to get rid of duplicate declarations, it's present to get rid of declarations that aren't wanted at all, which is a different matter entirely. For example suppose the stylesheet were like this:
xmlns:xsl=“http://www.w3.org/1999/XSL/Transform”
xmlns:var=“http://another.org/xslt”
/>
Once upon a time …
Then although the sequence constructor has not changed, the
xmlns:var=“http://another.org/xslt”>
Once upon a time …
Why can't the XSLT processor simply include all the namespaces that are actually used in element and attribute names, and omit the rest? The reason is that many XML applications, like XSLT itself, will use the namespace mechanism to create unique values within their own data. For example, namespace prefixes might be used in attribute values as well as attribute names. The XSLT processor can't distinguish these from ordinary values, so it has to play safe.
So if there are namespaces you don't want in the output tree, you can specify them in the
exclude-result-prefixes
attribute of the#default. If you want more precise control (though it is rarely needed), you can also specify
[xsl:]exclude-result-prefixes
on any element in the stylesheet, remembering that the attribute must be prefixed when it appears on a literal result element, and unprefixed when it appears on an XSLT element. It affects all literal result elements that are textually within its scope.