XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (18 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

If the
element in the null namespace, XHTML if it starts with an
element in the XHTML namespace, and XML otherwise.
Implementations may include output methods other than these four, but this is outside the scope of the standard. One mechanism provided by several products is to feed the result tree to a user-supplied document handler. In the case of Java products, this will generally be written to conform to the
ContentHandler
interface defined as part of the SAX2 API specification (which is part of the core class library in Java). Most implementations also provide mechanisms to capture the result as a DOM tree. Remember that if you use the result tree directly in this way, the XSLT processor will not serialize the tree, and therefore nothing you say in the
So, while the bulk of the XSLT Recommendation describes the transformation process from a source tree to a result tree, there is one section that describes another process, serialization. Because the serialization of a document tree as a file is a process that is relevant not only to XSLT but also to XQuery and potentially other applications in the future, the detail is no longer in the XSLT 2.0 Recommendation, but forms a W3C specification in its own right (see
http://www.w3.org/TR/xslt-xquery-serialization/
). For similar reasons, it has a chapter of its own in this book (Chapter 15). The name
serialization
is used because it turns a tree structure into a stream of characters or bytes, but it mustn't be confused with serialization in distributed object systems such as Component Object Model (COM) or Java, which produces a serial file representation of a COM or Java object. XSLT processors can implement this at their discretion, and it fits into our diagram as shown in
Figure 2-3
.
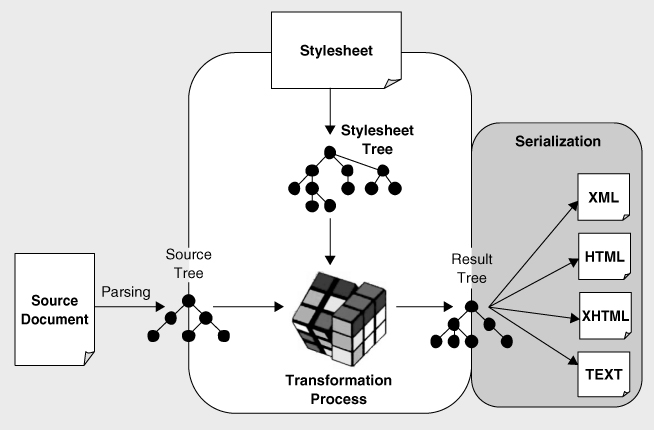
Multiple Inputs and Outputs
In real life, the processing model is further complicated because there can be multiple inputs and outputs. Specifically:
- There can be multiple input documents. The stylesheet can use the
doc()
or
document()
functions (described in Chapter 13, page 750) to load secondary input documents, based on URI references held in the source document or the stylesheet. Each input document is processed as a tree in its own right, in exactly the same way as the principal input document. It is also possible to supply additional input documents as parameters to the stylesheet, or to read an entire collection of documents using the
collection()
function. - The stylesheet may also consist of multiple documents. There are two declarations that can be used in the stylesheet,
- A single run of the XSLT processor can produce multiple output documents. This allows a single source document to be split into several output files: for example, the input might contain the text of an entire book, while the output contains one HTML file for each chapter, all connected using suitable hyperlinks. This capability, which is provided by the
The XDM Tree Model
Let's now look at the tree model used in XSLT and XPath, in a little more detail. It's defined in the W3C Specification
XQuery 1.0 and XPath 2.0 Data Model (XDM)
(
http://www.w3.org/TR/xpath-datamodel
): you can read XDM as standing for either XQuery Data Model or XPath Data Model (or even XML Data Model) as you prefer.
The XDM tree model is similar in many ways to the XML DOM. However, there are a number of differences of terminology and some subtle differences of detail. I'll point some of these out as we go along.
XML as a Tree
In this section, I will describe the XDM tree model of an XML document, and show how it relates to textual XML files containing angle brackets.
This isn't actually how the XDM specification does it: it adopts a more indirect approach, showing how the data model relates to the XML InfoSet (an abstract description of the information content of an XML document), and the Post Schema Validation Infoset (PSVI), which is defined in the XML Schema specifications to define the information that becomes available as a result of schema processing. The InfoSet is described in a W3C specification at
http://www.w3.org/TR/xml-infoset/
. The PSVI is described in the W3C Schema recommendations at
http://www.w3.org/TR/xmlschema-1/
.
At a simple level, the equivalence of the textual representation of an XML document with a tree representation is very straightforward.
Example: An XML Tree
Consider a document like this:
We can consider each piece of text as a leaf node, and each element as a containing node, and build an equivalent tree structure, as shown in
Figure 2-4
. I show the tree after the stripping of all whitespace nodes (in XSLT this can be achieved using the
- In the top cell, the
kind
of node - In the middle cell, the
name
of the node - In the bottom one, its
string value
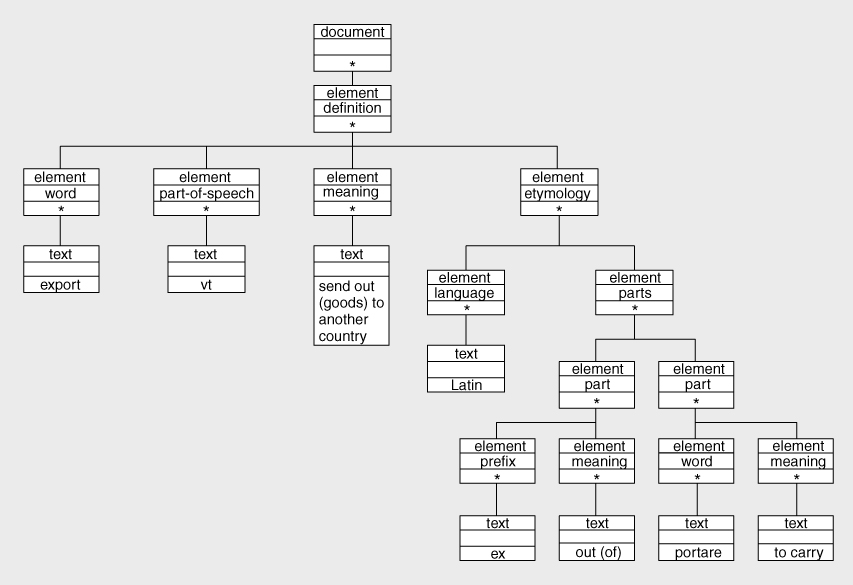
For the document node and for elements, I showed the string value simply as an asterisk; in fact, the string value of these nodes is defined as the concatenation of the string values of all the element and text nodes at the next level of the tree.
It is easy to see how other aspects of the XML document, for example, attributes and processing instructions, can be similarly represented in this tree view by means of additional kinds of nodes.
At the top of every tree, there is a
root
node (trees in computer science always grow upside down). Usually the root will be a document node, but we will look at other cases later on.
The terminology here has changed since XPath 1.0. What was the
root
node in XPath 1.0 is now called a
document
node. In XPath 2.0, it is possible to have element nodes, or indeed any kind of node, that have no parent. Any node that has no parent, whatever kind of node it is, can be considered to be the root of a tree. So the term “root” no longer refers to a particular kind of node, but rather to any node that has no parent, and is therefore at the top of a tree, even if that tree contains just one node.
An XDM document node performs the same function as the document node in the DOM model, in that it doesn't correspond to any particular part of the textual XML document, but you can regard it as representing the XML document as a whole. The children of the document node are the top-level elements, comments, processing instructions, and so on.
In the XML specification the outermost element is described as the “root or document element.” In XDM this element is not the root of the tree (because it has a parent, the document node), and the term “document element” is not normally used, because it is too easily confused with “document node.” I prefer to call it the “outermost element,” because that seems to cause least confusion.
The XDM tree model can represent every well-formed XML document, but it can also represent structures that are not well-formed according to the XML definition. Specifically, in well-formed XML, there must be a single outermost element containing all the other elements and text nodes. This element can be preceded and followed by comments and processing instructions, but it cannot be preceded or followed by other elements or text nodes.
XDM does not enforce this constraint—the document node can have any children that an element might have, including multiple elements and text nodes in any order. The document node might also have no children at all. This corresponds to the XML rules for the content of an
external general parsed entity
, which is a freestanding fragment of XML that can be incorporated into a well-formed document by means of an entity reference. I shall sometimes use the term
well balanced
to refer to such an entity. This term is not used in the XDM specification; rather, I have borrowed it from the largely forgotten XML fragment interchange proposal (
http://www.w3.org/TR/xml-fragment.html
). The essential feature of a well-balanced XML fragment is that every element start tag is balanced by a corresponding element end tag.
Example: Well-balanced XML Fragment
The following example shows an XML fragment that is well balanced but not well formed, as there is no enclosing element:
The
The corresponding XDM tree is shown in
Figure 2-5
. In this case it is important to retain whitespace, so spaces are shown using the symbol ♦.
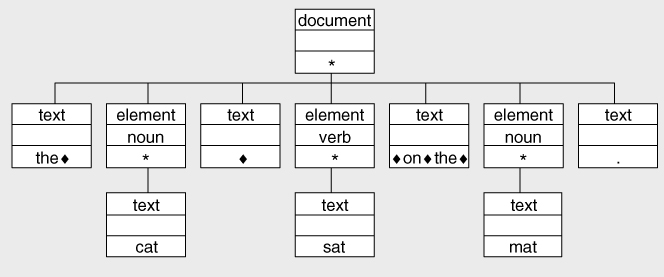
The string value of the document node in this example is simply:
The cat sat on the mat.
In practice the input and output of an XSLT transformation will usually be well-formed documents, but it is very common for temporary trees constructed in the course of processing to have more than one element as a child of the document node.
Nodes in the Tree Model
An XDM tree is made up of nodes. There are seven kinds of node. The different kinds of node correspond fairly directly to the components of the source XML document:
| Node Kind | Description |
| Document node | The document node is a singular node; there is one for each document. Do not confuse the document node with the document element, which in a well-formed document is the outermost element that contains all others. A document node never has a parent, so it is always the root of a tree. |
| Element node | An element is a part of a document bounded by start and end tags, or represented by a single empty-element tag such as . Try to avoid referring to elements as tags: elements generally have two tags, a start tag and an end tag. |
| Text node | A text node is a sequence of consecutive characters in a PCDATA part of an element. Text nodes are always made as big as possible: there will never be two adjacent text nodes in the tree, because they will always be merged into one. (This is the theory. Some implementations don't always follow this rule) |
| Attribute node | An attribute node includes the name and value of an attribute written within an element start tag (or empty element tag). An attribute that was not present in the tag, but which has a default value defined in the DTD or Schema, is also represented as an attribute node on each separate element instance. A namespace declaration (an attribute whose name is xmlns xmlns or whose name begins withxmlns:) is, however, or whose name begins withxmlns:) is, however,not represented by an attribute node in the tree. |
| Comment node | A comment node represents a comment written in the XML source document between the delimiters |
| Processing instruction node | A processing instruction node represents a processing instruction written in the XML source document between the delimitersand?>. The PITarget from the XML source is taken as the node's name and the rest of the content as its value. Note that the XML declaration version=“1.0”?> is not a processing instruction, even though it looks like one, and it is not represented by a node in the tree. |
| Namespace node | A namespace node represents a namespace declaration, except that it is copied to each element that it applies to. So each element node has one namespace node for every namespace declaration that is in scope for the element. The namespace nodes belonging to one element are distinct from those belonging to another element, even when they are derived from the same namespace declaration in the source document. |