XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (133 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

Output
The precise layout of the HTML depends on which XSLT processor you are using, but apart from layout details it should start like this:
SCENE I. Venice. A street.
Cast: RODERIGO, IAGO, BRABANTIO
Enter RODERIGO and IAGO
RODERIGO
Tush! never tell me; I take it much unkindly
That thou, Iago, who hast had my purse
As if the strings were thine, shouldst know of this.
IAGO
'Sblood, but you will not hear me:
If ever I did dream of such a matter, Abhor me.
…
It is sometimes useful to use named modes, even where they are not strictly necessary, to document more clearly the relationship between calling templates and called templates, and to constrain the selection of template rules rather more visibly than can be achieved by relying on template rule priorities. This might even improve performance by reducing the number of rules to be considered, though the effect is likely to be marginal.
For example, suppose that a
…
…
…
…
This relies on the default priority rules to ensure that the correct template rule is applied to each stanza—as explained in Chapter 12, the default priority for the pattern stanza[1]
stanza[1] is higher than the default priority forstanza.
is higher than the default priority forstanza.
Another way of doing this, perhaps less orthodox but equally effective, is as follows:
…
…
…
…
Another solution, giving even finer control, would be to use
Which you choose is largely a matter of personal style, and it is very hard to argue that one is better than the other in all cases. However, if you find that the match patterns used in defining a template rule are becoming extremely complex and context dependent, then you probably have both a performance and a maintenance problem on your hands, and controlling the selection of template rules in the calling code, by using modes or by calling templates by name, may well be the answer.
Simulating Higher Order Functions
In functional programming languages, a very useful programming technique is to write a function that accepts another function as an argument. This is known as a higher order function. For example, you might write a function that does a depth-first traversal of a tree and processes each node in the tree using a function that is supplied as an argument. This makes it possible to use one tree-walking routine to achieve many different effects (you might recognize this as the
Visitor Pattern
).
In XSLT (and XPath), functions are not first-class objects, so they cannot be passed as arguments to other functions. The same is true of templates. However, the template-matching capability of
This use of
http://fxsl.sourceforge.net/
), which provides many examples of the technique.
A simple example of a higher order function found in many functional programming languages is the
fold
function. Given as an argument a function that adds two numbers,
fold
will find the sum of all the numbers in a sequence. Given a function that multiplies two numbers, it will find the product of the numbers in the sequence. In fact,
fold
takes three arguments: the sequence to be processed, the function to process two values, and the initial value. It turns out that the
fold
function can be used, with suitable arguments, to perform a wide variety of aggregation functions on sequences.
The key to the Novatchev technique is that although you cannot pass a function or template as an argument to another function or template, you can pass a node, and you can use
Rather than show you how
fold
works, which you can find out on the FXSL Web site, I will use another example that makes greater use of the new capabilities in XSLT 2.0. A common problem is to check whether there are cycles in your data. For example, your data might represent a part explosion, and you want to check that no part is a component of itself, directly or indirectly. Or you might be checking an XSLT stylesheet to check that no attribute set is defined in terms of itself. (There is an example that shows how to do this conventionally, without a higher order function, under
Example: Checking for Cycles in a Graph
This example provides a generic procedure to look for cycles in a graph and then applies this procedure to a data file to see if the ID/IDREF links are cyclic.
In essence, the algorithm to check for a cycle is this: given a function
links(A)
that returns the set of nodes to which
A
is directly linked, the function
refers(A,B)
is true if
links(A)
includes
B
(that is, if there is a direct reference) or if there is a node
C
in the result of
links(A)
such that
refers(C,B)
is true (this is an indirect reference via C). This is a recursive definition, of course, and it is implemented by a recursive function. Finally, you know that
A
participates in a cycle if
refers(A,A)
is true. In coding the function, we have to be careful to ensure that the implementation will never go into a loop, remembering that a node reachable from A might participate in a cycle even if A does not (for a simple example, consider a graph in which A refers to X and X refers to itself). To achieve this, we pass an extra parameter indicating the route by which a node was reached, and we ignore nodes that were already on the route (we could report a cycle if we find them; but we've actually written this code to test whether a specific node participates in a cycle, which isn't the same thing).
Stylesheet
The stylesheet that searches for cycles in a graph is in
cycle.xsl
.
You can implement the
refers
function like this:
(some $C in ($direct except $route)
satisfies graph:refers($links, $C, $B, ($route, $C)))”/>
When you call this higher order function, you need to supply a node as the
$links
argument that will always cause a particular template rule to be invoked. Let's do this for the case where the link is established by virtue of the fact that the first node contains an
idref
attribute whose value matches the
id
attribute of the node that it references. This is in
idref-cycle.xsl
:
And now you can test whether the context node participates in a cycle like this:
Let's look at the details of how this works:
The higher order function is implemented using
The code to follow a link is implemented as a template rule, and is invoked using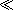 as=“element()”
as=“element()”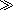 attribute on the
attribute on the
Unlike conventional template rules that create new nodes, this particular rule returns a reference to a sequence of existing nodes: specifically, the nodes selected by the
select
attribute of theasattribute, which means that the result of the variable is the sequence of nodes returned by the template. Without theasattribute, the nodes would be copied to make a temporary document, which wouldn't work, because the XPath
intersect
operator relies on the nodes in the variable
$direct
having their original identity (used in the way it is used here, it tests whether
$B
is one of the nodes in
$direct
).
The important thing about this stylesheet is that the module
cycle.xsl
is completely general purpose: it has no knowledge of how the links between nodes are represented, and can therefore be used to look for cycles in any graph, however it is implemented.
Source
Two source files are supplied:
acyclic-data.xml
and
cyclic-data.xml
. Here is the one containing a cycle:
]>
Output
Running the stylesheet
idref-cycle.xsl
against the source file
cyclic-data.xml
simply produces an error message saying that the data contains a cycle.