XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (109 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

Secondly, consider functions that return an integer, such as
month-from-date()
. Here the result is always in the range 1 to 12. So the result could have been defined as an
xs:byte
or an
xs:integer
or an
xs:positiveInteger
or several other types. Alternatively, a new type,
xs:month-value
, could have been defined with the specific range 1 to 12. Defining it as
xs:byte
would have been helpful to people who want to use the returned value in a call to a function that expects an
xs:byte
, while defining it as an
xs:positiveInteger
would have helped people who want to call functions that expect that type. Defining a custom type just for this purpose would have been overkill. It's not possible to please everyone, so the plain vanilla type
xs:integer
was chosen to stay neutral.
The fact of the matter is that numeric ranges don't naturally fall into a hierarchy, and type checking by looking at the labels rather than the actual value doesn't work particularly well in this situation. Choosing a type such as
xs:int
may give performance advantages on some systems compared with
xs:long
, but they are likely to be miniscule. My advice would be either to define a type that reflects the actual semantics of the value, for example
percentage
or
class-size
or
grade
, or just use the generic type
xs:integer
. If you write general-purpose functions in XSLT or XQuery, then declare the expected type as
xs:integer
, and check the validity of the actual value within the code of your function.
Some people advocate defining numeric types for different units of measure; for example, inches or centimeters. If you find this useful to document the intended usage, then that's fine, but don't expect the type system to do anything clever with the values as a result. It won't stop you adding an inches value to a centimeters value, for example. My personal preference is to model units of measure as complex types, typically using an element whose content is the numeric value, and with a fixed, defaulted attribute to denote the unit of measure. Subtypes are designed to be used where values of the subtype are substitutable for values of the parent type, which means they aren't appropriate if you want to restrict the operations that are permissible.
Derived String Types
As well as types derived from
xs:integer
, the repertoire of types that come as standard with XML Schema include a family of types derived from
xs:string
. The type hierarchy is shown in
Figure 5-3
.
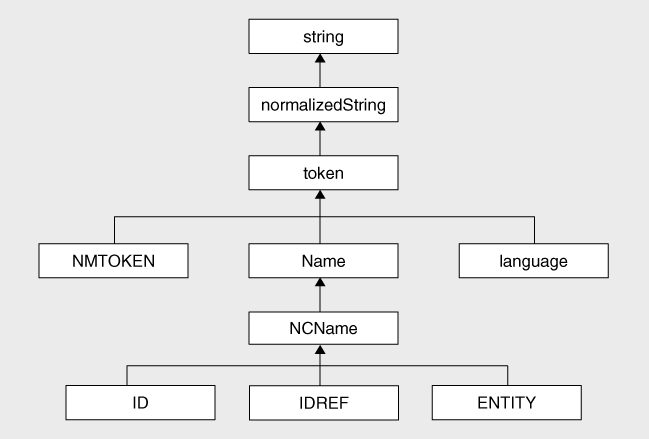
Most of these types restrict the set of characters that are allowed to appear in the string, but they also have other purposes:
- Some affect the way that whitespace within the value is normalized
- Some such as
xs:ID
and
xs:IDREF
trigger special validation rules that apply to the document as a whole
The processing of whitespace within an element or attribute value is controlled in XML Schema using the
xs:whiteSpace
facet on the type. There are three possible values:
preserve
,
replace
, and
collapse
. These work as follows:
- preserve
leaves the value intact. - replace
replaces each tab, carriage return, or newline character with a single space. - collapse
removes leading and trailing whitespace, and replaces any sequence of internal whitespace characters by a single space character. (
Whitespace
here means any of the characters
x09
,
x0A
,
x0D
, and
x20
, while
space
means the character
x20
.)
Validation of a source document against a schema only happens after XML parsing is complete, so this level of whitespace processing only comes into play after the XML parser has already done its work. The XML parser replaces any end-of-line sequence (for example,
x0Dx0A
) by a single newline character (
x0A
), unless it is written using character references such as
 , and it also normalizes attribute values using the
, and it also normalizes attribute values using the
replace
rule above. Specifying
preserve
in the schema won't stop the XML parser replacing tabs in an attribute value by spaces, unless you write them as .
In practice, you choose the whitespace processing you want not by specifying an explicit
xs:whiteSpace
facet, but by deriving your type definition from
xs:string
if you want
preserve
,
xs:normalizedString
if you want
replace
, and
xs:token
if you want
collapse
. (The type
xs:token
is a notorious misnomer, it actually represents a sequence of tokens separated by whitespace, and the assumption is that it makes no difference which whitespace characters are used as separators.)
You can restrict the allowed values for a string using the
xs:pattern
facet, which provides a regular expression that the value must match. The pattern is applied to the value after whitespace processing has been carried out.
Patterns can also be used for types other than strings, but they are rather blunt instruments. For example, if you try to define a subtype of
xs:decimal
with the pattern[0-9]+\.[0-9]{2}, which states that there must be two digits after the decimal point, then any attempt to cast a value to this type is likely to fail—the system isn't clever enough to add trailing zeros to the value just because the pattern requires them.
Oddly, XML Schema doesn't define a type for strings in which spaces are not allowed, such as part numbers. It's often handy to define such a type as a user-defined type, from which many other application-oriented types can be derived. You can define it like this:
\s]+”/>
This pattern also restricts the value to contain at least one non-space character (a zero-length string is not allowed).
The meaning of each of the types is summarized in the table below.
| Type | Usage |
| xs:string | Any sequence of characters, in which whitespace is significant. |
| xs:normalizedString | Any sequence of characters, in which whitespace acts as a separator, but no distinction is made between different whitespace characters. |
| xs:token | A sequence of tokens separated by whitespace. |
| xs:language | A value that follows the rules for the xml:lang attribute in XML. |
| xs:NMTOKEN | A sequence of characters classified as name characters in the XML specification. This includes letters, digits,.,-,_, and:, and a few other special characters. |
| xs:Name | An NMTOKEN that starts with a character classified as an initial name character in the XML specification. These include letters, _, and:. |
| xs:NCName | A Name that does not include a :(a no-colon-name). |