The Naked Future (5 page)
Authors: Patrick Tucker

Most people who download Instagram, Twitter, or Facebook to their phone already understand, at least in part, that they're risking their personal private information in doing so. But they probably wouldn't elect to give their
grandparents'
contact information and other personal details to some strange company. Given that more than 9 percent of the entire U.S. population is part of a
geo-social network (as calculated from the fact that 18 percent of smartphone owners are part of a geo-social network, and well more than 50 percent of the population owns a smartphone), further incidents of data leakage will affect the U.S. population well beyond the smartphone-owning community.
We presume that our personal data is compromised only when we
choose
to take a certain risky action. Maybe some people find amusement in these silly networks and don't mind giving away their information to strangers, but that shouldn't have any bearing on
me,
goes this line of thinking. But our friends and loved ones create data about life and that data includes us, whether we wish to be tagged or not. This is why we are using the wrong set of words to explain this phenomenon; we think of data leakage as an act of theft but we need to understand it as a contagion event. If you know someone who geo-tags their tweets, Facebook posts, or Instagram photos, you've already been infected.
Once these signals are sensed, they must be processed if they are to form the basis of a useful prediction. But predictionsâlike the future itselfâspring from the brain. The challenge is getting computers, programs, and systems to make predictions on the basis of continuously sensed information, on the basis of what's happening now in (sort of) the same way that the brain does. This is an entirely recent problem related to the rise of continuous data streams and all the artifacts of modern information overload. But the mathematical formula to tackle it has actually been around for centuries and can be utilized as easily by a college undergrad as by a roomful of scientists.
Researchers use plenty of statistical methods, and mathematical tricks can be employed, in isolation or combination, to turn data into a prediction. But the one method that allows you to make new predictions and update old predictions on the basis of new
information is named after its founder, Thomas Bayes. The theorem in its simplest form is:
Â
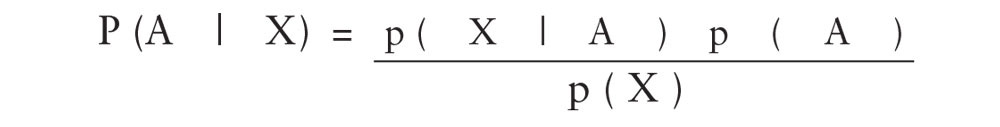
In the above,
P
is probability,
A
is the outcome we are trying to predict, and
X
is some condition that could affect
P
. The theory solves for
A
given ( | )
X
. The value you award
P
when you begin is sometimes called the “prior”; the value you award
P
after you've run the formula is called the “posterior
.
”
Undeniably, compared with other statistical methods Bayes won't always give you the most
accurate
answer based on the data that you're looking at. But it does give you a fairly honest answer. A large gap (in value) between the prior and the posterior suggests a small degree of confidence.
Celebrated artificial intelligence (AI) luminary and statistician Judea Pearl describes the process as follows: the Bayesian interpretation of probability is one in which we “encode degrees of belief about events in the world, and data are used to strengthen, update or weaken those beliefs.”
17
Compared with many other statistical methods such as traditional linear regression, Bayes is one of the most like the brain. Predictions of probability combine past experience with sensed input to create a (somewhat) moving picture of the future.
What's important to understand is that although Thomas Bayes's formula wasn't published until 1764, about three years after his death, it's only in the last couple of decades that Bayes has come to be seen as the essential lens through which to understand probability in a wide number of contexts. The Bayesian formula plays a critical role in statistical research methods having to deal with computer and AI problems but also the simple questions of quantifying what may happen.
When I asked the researchers in this book why they found
Bayes more useful than other statistical methods for their work, the most common response I received was that Bayesian inference allows you to update a probability assumptionâthe degree of faith you have in a particular outcomeâon the basis of new information, new details, and new facts, and to do so very quickly. If the interconnected age has taught us nothing else, it is that there will
always
be new facts. Bayes lets you speedily move closer to a better answer on the basis of new information.
Here's an example. Let's say it's Tuesday and you are scheduled to meet your therapist. Your therapist has never missed a Tuesday appointment so you hypothesize that the probability of her showing up is 100 percent. The
P
for
A
or
P(A)
= 1. This is your
prior
belief. Obviously, it's terrible. There is never a 100 percent chance that someone will show up to work. Now, let's say you get some new information, that your therapist has just left from a previous appointment and she is three miles away, on foot. How would you go about adjusting your belief to more accurately reflect the probability that your therapist will make it to your appointment on time?
Let's say you find some new data, that the average walking speed is 3.1 miles per hour. Given time and distance you can compute that your therapist will surely be late. But you must compute this in light of the prior value; your therapist is
never
late. You now know the chances of your therapist being late for this appointment are lower than they would be for a regular person but the possibility of her being late for your appointment, in spite of what you understand to be the lessons of all history, have grown significantly. Now you discover even more information: according to reviews of your therapist's practice on Yelp, she's actually late to her appointments about half the time. You can recompute the probability of your therapist's getting to the appointment on time over and over, every time you get some new tidbit that reveals reality more clearly in all its inconvenience. What is making the future more transparent is the exponentially growing number of tidbits we have to work with. Bayes lets us manage that growth.
Imagine next that you have an enormous amount of telemetrically gathered information to update your prior assumption. You can actually track your therapist moving toward you in real time through her Nike+ profile. You can read the wind currents meeting her via Cosm's feed off a nearby wind sensor. You can measure her heart rate and hundreds of other signals that might further refine your understanding of where she is going to be, relative to you, in the next few minutes. Let's say you also have access to an enormous supercomputer capable of running thousands of simulations a minute, enabling you to weigh and average each new variable and piece of information more accurately. The influence of your first hilarious off-the-mark prior assumption about your therapist's perfect punctuality is, through this process, dissolved down to nothing.
This is the promise of
sensed
data, of telemetrics combined with easy-to-update statistical tools such as Bayes.
In March 2010, Adam Sadilek, a young Czech-born researcher from the University of Rochester, set out with some colleagues to see how accurately they could predict the location of someone who had turned off his or her GPS, who wasn't geo-tagging tweets or posts, who was in effect going incognito. Sadilek and his team sampled the tweets of more than 1.2 million individuals across New York City and Los Angeles (America's chirpiest cities). After a month, the team had more than 26 million individual messages with which to work; 7.6 million of those tweets were geo-tagged.
They trained an algorithm using Bayesian machine learning to explore the potential patterns among the Tweeters. The idea was to uncover the conversations between the users, contextualize what conversations were taking place across the New York and Los Angeles landscapes, and see if they could use that information to discover information about people who were friends with the geo-taggers but who weren't themselves geo-tagging.
Turns out that your friends' geo-tagged tweets provide a great indication of where you've been, even if you weren't in that place with that friend. Because you, like most people, are probably a creature of habit, where you've been is an excellent indicator of where you're going.
Let's say Sadilek's system has no “historical information” on you. You don't geo-tag tweets; you keep your phone's GPS setting off; you are invisible, a covert operative. But in order to maintain your cover, you established a Twitter account using a dummy e-mail address. Let's also say you've got two friends on Twitter. They're real friends, people you talk to about events in real life and with whom you relate in the real world. You see them in class, at clubs, in line at the post office. Like a lot of other people, these two friends do geo-tag their tweets. Sadilek's system can predict
your
location at any moment (down to 328 feet and within a twenty-minute frame) with 47 percent accuracy. That means he's got a 50 percent chance of catching you at any given moment.
18
I know, I know, you did everything right. You were a careful steward of your privacy. It's not fair that a twenty-five-year-old PhD grad from Czechoslovakia should be able to find out so much about you so effortlessly. It was your friends who gave you away without even realizing it. Now your not-so-secret-agent career is over.
I went to meet Sadilek at an AI conference. Sitting in the executive lounge on the top floor of the Toronto Sheraton, we overlooked downtown and saw people parking their bicycles, waiting for buses, talking on phones, walking with heads pointed toward shoes, white iPod cords dangling from their ears, people coming and going from little secret rendezvous that every one of them presumed were unknowable to the outside world. We talked a bit about human predictability.
“Somehow, growing up as a teenager, I always was sort of put off by how predictable people are. I never liked that. I liked people that were random.”
Since entering the field of machine learning, Sadilek has come
face-to-face with a hard truth. Human behavior is far more predictable than anyone ever predicted; surprisingly predictable you may even say. One experiment in particular proved this in a way that astounded even Sadilek.
The year was 2011 and he was about to start an internship at Microsoft with researcher John Krumm. In his years of working at Microsoft, at a time when the company was at its most ambitious and adventurous, Krumm was able to amass a rather unique data set. He set out to make a sort of living map of human mobility the way zoologists and biologists track the movement of bears or birds or lions; but because Microsoft was so flush with cash at the time, Krumm paid several hundred test subjects to carry GPS trackers around with them wherever they went, which broadcasted the wearers' physical location every couple of seconds. Some people carried the trackers in their pockets and some had the tracker installed on the dashboard of their cars. Microsoft was considering a lot of potential uses for this data, from helping cities better understand traffic patterns to developing a new line of smart thermostats that could predict when customers were on their way home and accordingly turn on the heat. Another potential use was an intelligent calendar to be used in conjunction with Outlook (the default e-mail provider that comes with Windows), which could forecast your potential availability for appointments into the future. Krumm watched the trackers and the people to which they were connected sail through life for more than six years. Altogether, his seven hundredâplus subjects provided more than ninety years' worth of data on human mobility.
He presented the data set to Sadilek and they applied an algebraic technique called eigendecomposition to it. Decomposition in this sense simply means reducing a lot of numbers to a single value that's in some way characteristic of the whole. Eigen is derived from the German word for “self.” Through eigendecomposition Sadilek and Krumm were able to create a model that could predict a subject's location with higher than 80 percent accuracy up to eighty weeks in advance.
19
Put another way, based on information stored in your phone, Sadilek and Krumm's model can predict where you will beâdown to the hour and within a square blockâ
one year and a half from right now.
Granted, Krumm and Sadilek's data set isn't a typical one. Most of us don't share geo-location information as frequently as did the folks Krumm put on the payroll. At least not yet. And most of us bounce between home, work, or school and back pretty regularly. In fact, if you know where someone usually is on a Monday at 10
A.M
. you can infer their location on any given Monday at 10
A.M
. fairly well, but it's still just a guess based on two data points. The magic of Sadilek and Krumm's Far Out model, as they named it, is that it factors in the occasional random detourâthe flat tire, the unexpected work junket, or the sick dayâwithout making those outlier events more significant than they are, without overfitting.