Gödel, Escher, Bach: An Eternal Golden Braid (92 page)
Read Gödel, Escher, Bach: An Eternal Golden Braid Online
Authors: Douglas R. Hofstadter
Tags: #Computers, #Art, #Classical, #Symmetry, #Bach; Johann Sebastian, #Individual Artists, #Science, #Science & Technology, #Philosophy, #General, #Metamathematics, #Intelligence (AI) & Semantics, #G'odel; Kurt, #Music, #Logic, #Biography & Autobiography, #Mathematics, #Genres & Styles, #Artificial Intelligence, #Escher; M. C

cycle goes on and on. This can go on for any number of stages; the hope is that eventually, among the strands which are present at some point, there
will be found two copies of the original strand (one of the copies may be, in fact, the original strand).
The Central Dogma of Typogenetics
Typogenetical processes can be represented in skeletal form in a diagram (Fig. 90).
This diagram illustrates the
Central Dogma of Typogenetics
. It shows how strands define enzymes (via the Typogenetic Code); and how in turn, enzymes act back on the strands which gave rise to them, yielding new strands. Therefore, the line on the left portrays how old information flows upwards, in the sense that an enzyme is a translation of a strand, and contains therefore the same information as the strand, only in a different form-in particular; in an active form. The line on the right, however, does not show information flowing downwards; instead, it shows how
new information gets created
: by the shunting of symbols in strands.
An enzyme in Typogenetics, like a rule of inference in a formal system, blindly shunts symbols in strands without regard to any "meaning" which may lurk in those symbols.
So there is a curious mixture of levels here. On the one hand, strands are acted upon, and therefore play the role of data (as is indicated by the arrow on the right); on the other hand, they also dictate the actions which are to be performed on the data, and therefore they play the role of
programs
(as is indicated by the arrow on the left). It is the player of Typogenetics who acts as interpreter and processor, of course. The two-way street which links "upper" and
"lower" levels of Typogenetics shows that, in fact, neither strands nor enzymes can be thought of as being on a higher level than the other. By contrast, a picture of the
Central
Dogma of the
MIU
-system looks this way:
In the
MIU
-system, there is a clear distinction of levels: rules of inference simply belong to a higher level than strings. Similarly for TNT, and all formal systems.

Strange Loops, TNT, and Real Genetics
However, we have seen that in
TNT
, levels are mixed, in another sense. In fact, the distinction between language and metalanguage breaks down: statements about the system get mirrored inside the system. It turns out that if we make a diagram showing the relationship between TNT and its metalanguage, we will produce something which resembles in a remarkable way the diagram which represents the Central Dogma of Molecular Biology.
In fact, it is our goal to make this comparison in detail; but to do so, we need to indicate the places where Typogenetics and true genetics coincide, and where they differ. Of course, real genetics is far more complex than Typogenetics-but the "conceptual skeleton" which the reader has acquired in understanding Typogenetics will be very useful as a guide in the labyrinth of true genetics.
DNA and Nucleotides
We begin by discussing the relationship between "strands", and
DNA
. The initials "DNA"
stand for "deoxyribonucleic acid". The
DNA
of most cells resides in the cell's nucleus, which is a small area protected by a membrane. Gunther Stent has characterized the nucleus as the
"throne room" of the cell, with
DNA
acting as the ruler. DNA consists of long chains of relatively simple molecules called nucleotides. Each nucleotide is made up of three parts: (1) a phosphate group stripped of one special oxygen atom, whence the prefix "deoxy"; (2) a sugar called "ribose", and (3) a base. It is the base alone which distinguishes one nucleotide from another; thus it suffices to specify its base to identify a nucleotide. The four types of bases which occur in
DNA
nucleotides are:
(Also see Fig. 91.) It is easy to remember which ones are pyrimidines because the first vowel in "cytosine", "thymine", and "pyrimidine" is 'y'. Later, when we talk about
RNA
, "uracil"-
also a pyrimidine-will come in and wreck the pattern, unfortunately. (Note: Letters representing nucleotides in real genetics will not be in the
Quadrata
font, as they were in Typogenetics.)
A single strand of
DNA
thus consists of many nucleotides strung together like a chain of beads. The chemical bond which links a nucleotide to its two neighbors is very strong; such bonds are called
covalent bonds
, and the "chain of beads" is often called the
covalent
backbone
of
DNA
.
Now
DNA
usually comes in double strands-that is, two single strands which are paired up, nucleotide by nucleotide (see Fig. 92). It is the bases
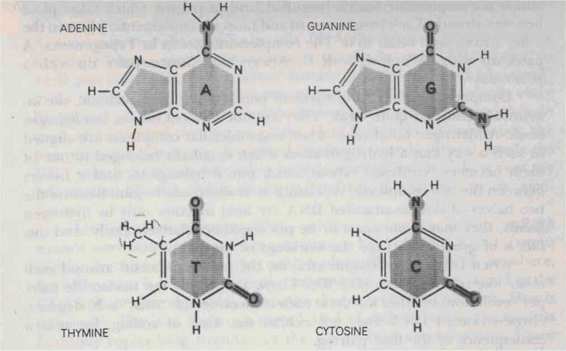
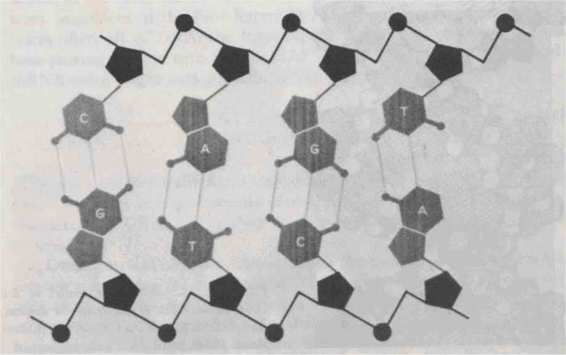
FIGURE 91. The four constituent bases of DNA: Adenine, Guanine, Thymine, Cytosine.
[From Hanawalt and Haynes, The Chemical Basis of Life (San Francisco: W. H. Freeman, 1973), p. 142.J
FIGURE 92. DNA structure resembles a ladder in which the side pieces consist of alternating units of deoxyrihose and phosphate. The rungs are formed by the bases paired in a special way, A with T and G with C, and held together respectively by two and three hydrogen bonds. [From Hanawalt and Haynes, The Chemical Basis of Life, p. 142.
which are responsible for the peculiar kind of pairing which takes place between strands.
Each base in one strand faces a complementary base in the other strand, and binds to it. The complements are as in Typogenetics: A pairs up with T, and C with G. Always one purine pairs up with a pyrimidine.
Compared to the strong covalent bonds along the backbone, the interstrand bonds are quite weak. They are not covalent bonds, but hydrogen bonds. A hydrogen bond arises when two molecular complexes are aligned in such a way that a hydrogen atom which originally belonged to one of them becomes "confused" about which one it belongs to, and it hovers between the two complexes, vacillating as to which one to join. Because the two halves of double-stranded DNA are held together only by hydrogen bonds, they may come apart or be put together relatively easily; and this fact is of great import for the workings of the cell.
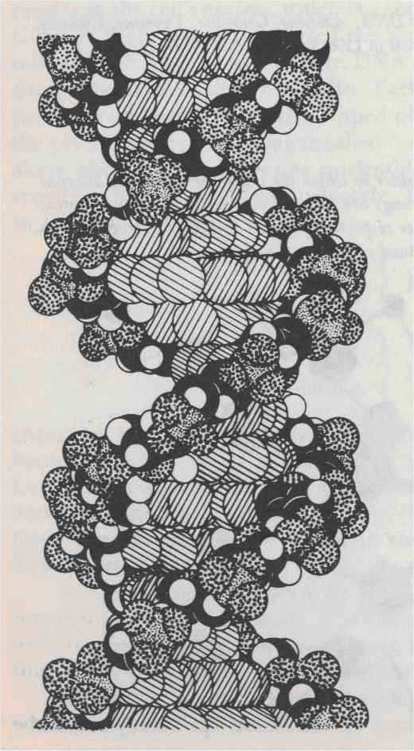
When DNA forms double strands, the two strands curl around each other like twisting vines (Fig. 93). There are exactly ten nucleotide pairs per revolution; in other words, at each nucleotide, the "twist" is 36 degrees. Single-stranded DNA does not exhibit this kind of coiling, for it is a consequence of the base-pairing.
FIGURE 93. Molecular model of the DNA double helix. [From Vernon M. Ingram, Biosynthesis (Menlo Park, Calif.: W. A. Benjamin, 1972)
Messenger KNA and Ribosomes
As was mentioned above, in many cells, DNA, the ruler of the cell, dwells in its private
"throne room": the nucleus of the cell. But most of the "living" in a cell goes on outside of the nucleus, namely in the
cytoplasm
-the "ground" to the nucleus' "figure". In particular,
enzymes
, which make practically every life process go, are manufactured by
ribosomes
in the cytoplasm, and they do most of their work in the cytoplasm. And just as in Typogenetics, the blueprints for all enzymes are stored inside the strands-that is, inside the DNA, which remains protected in its little nuclear home. So how does the information about enzyme structure get from the nucleus to the ribosomes'
Here is where
messenger
RNA
-m
RNA
-comes in. Earlier, m
RNA
strands were humorously said to constitute a kind of
DNA
Rapid Transit Service; by this is meant not that m
RNA
physically carries
DNA
anywhere, but rather that it serves to carry the information, or message, stored in the
DNA
in its nuclear chambers, out to the ribosomes in the cytoplasm.
How is this done? The idea is easy: a special kind of enzyme inside the nucleus faithfully copies long stretches of the
DNA's
base sequence onto a new strand-a strand of messenger RNA. This m
RNA
then departs from the nucleus and wanders out into the cytoplasm, where it runs into many ribosomes which begin doing their enzyme-creating work on it.
The process by which
DNA
gets copied onto m
RNA
inside the nucleus is called
transcription
; in it, the double-stranded DNA must be temporarily separated into two single strands, one of which serves as a template for the mRNA. Incidentally, "
RNA
" stands for
"ribonucleic acid", and it is very much like
DNA
except that all of its nucleotides possess that special oxygen atom in the phosphate group which
DNA's
nucleotides lack. Therefore the
"deoxy" prefix is dropped. Also, instead of thymine,
RNA
uses the' base uracil, so the information in strands of
RNA
can be represented by arbitrary sequences of the four letters
'A', 'C', 'G', 'U'
. Now when mRNA is transcribed off of
DNA
, the transcription process operates via the usual base-pairing (except with
U
instead of
T
), so that a
DNA
-template and its m
RNA
-mate might look something like this:
DNA:
GGTAAATCAAGTCA
(template)
m
RNA
:
GGCAUUUAGUCAGU
(copy")
RNA
does not generally form long double strands with itself, although it can. Therefore it is prevalently found not in the helical form which so characterizes
DNA
, but rather in long, somewhat randomly curving strands.
Once a strand of mRNA has escaped the nucleus, it encounters those strange subcellular creatures called "ribosomes"-but before we go on to explain how a ribosome uses m
RNA
, I want to make some comments about enzymes and proteins. Enzymes belong to the general category of biomolecules called
proteins
, and the job of ribosomes is to make all pro teins, not just enzymes. Proteins which are not enzymes are much more passive kinds of beings: many of them, for instance, are structural molecules, which means that they are like girders and beams and so forth in buildings: they hold the cell's parts together. There are other kinds of proteins, but for our purposes. the principal proteins are enzymes, and I will henceforth not make a sharp distinction.