Bad Pharma: How Drug Companies Mislead Doctors and Harm Patients (27 page)
Read Bad Pharma: How Drug Companies Mislead Doctors and Harm Patients Online
Authors: Ben Goldacre

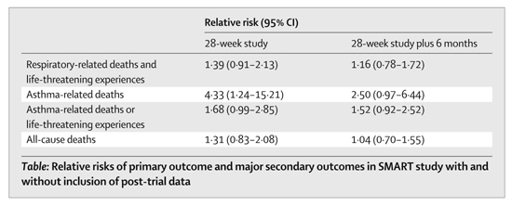
It took a couple of years from the end of the trial for these results to be published in an academic paper, read by doctors. Similarly, it took a long time for the label on the drug to explain the findings from this study.
There are two interesting lessons to be learnt from this episode, as Lurie and Wolfe point out. Firstly, it was possible for a company to slow down the news of an adverse finding reaching clinicians and patients, even though the treatment was in widespread use, for a considerable period of time. This is something we have seen before. And secondly, we would never have known about any of this if the activities of the FDA Advisory Committees hadn’t been at least partially open to public scrutiny, because ‘many eyes’ are often necessary to spot hidden flaws in data. Again, this is something we have seen before.
GSK responded in the
Lancet
that the twelve-month data was the only data analysed by the trial’s board, which was independent of the company (the trial was run by a CRO).
17
It said that it communicated the risks urgently, sent a letter to doctors who’d prescribed salmeterol in January 2003, when the trial was formally stopped, and that a similar notice appeared on the GSK and FDA websites, stating that there was a problem.
Trials that are too small
A small trial is fine, if your drug is consistently life-saving in a condition that is consistently fatal. But you need a large trial to detect a small difference between two treatments; and you need a very large trial to be confident that two drugs are equally effective.
If there’s one thing everybody thinks they know about research, it’s that a bigger number of participants means a better study. That is true, but it’s not the only factor. The benefit of more participants is that it evens out the random variation among them. If you’ve run a tiny trial of an amazing concentration-enhancing drug, with ten people in each group, then if only one person in one group had a big party the night before your concentration test, their performance alone could mess up your findings. If you have lots of participants, this sort of irritating noise evens itself out.
It’s worth remembering, though, that sometimes a small study can be adequate, as the sample size required for a trial depends on a number of factors. For example, if you have a disease where everyone who gets it dies within a day, and you have a drug that you claim will cure this disease immediately, you won’t need very many participants at all to show that your drug works. If the difference you’re trying to detect between the two treatment groups is very subtle, though, you’ll need many more participants to be able to detect this tiny difference against the natural background of everyday unpredictable variation in health for all the individuals in your study.
Sometimes you see a suspiciously large number of small trials being published on a drug, and when this happens it’s reasonable to suspect that they might be marketing devices – a barrage of publications – rather than genuine acts of scientific enquiry. We’ll also see an even more heinous example of marketing techniques in the section on ‘marketing trials’ shortly.
But there’s a methodologically interesting problem hiding in here too. When you are planning a trial to detect a difference between two groups of patients, on two different treatments, you do something called a ‘power calculation’. This tells you how many patients you will need if you’re to have – say – an 80 per cent chance of detecting a true 20 per cent difference in deaths, given the expected frequency of deaths in your participants. If you complete your trials and find no difference in deaths between the two treatments, that means you cannot find evidence that one is better than the other.
This is not the same as showing that they are equivalent. If you want to be able to say that two treatments are equivalent, then for dismally complicated technical reasons (I had to draw a line somewhere) you need a much larger number of participants.
People often forget that. For example, the INSIGHT trial was set up to see if nifedipine was better than co-amilozide for treating high blood pressure. It found no evidence that it was. At the time, the paper said the two drugs had been found to be equivalent. They hadn’t.
18
Many academics and doctors enjoyed pointing that out in the letters that followed.
Trials that measure uninformative outcomes
Blood tests are easy to measure, and often respond very neatly to a dose of a drug; but patients care more about whether they are suffering, or dead, than they do about the numbers printed on a lab report.
This is something we have already covered in the previous chapter, but it bears repeating, because it’s impossible to overstate how many gaps have been left in our clinical knowledge through unjustified, blind faith in surrogate outcomes. Trials have been done comparing a statin against placebo, and these have shown that they save lives rather well. Trials have also compared one statin with another: but these all use cholesterol as a surrogate outcome. Nobody has ever compared the statins against each other to measure which is best at preventing death. This is a truly staggering oversight, when you consider that tens of millions of people around the world have taken these drugs, and for many, many years. If just one of them is only 2 per cent better at preventing heart attacks than the others, we are permitting a vast number of avoidable deaths, every day of the week. These tens of millions of patients are being exposed to unnecessary risk, because the drugs they are taking haven’t been appropriately compared with each other; but each one of those patients is capable of producing data that could be used to compile new knowledge about which drug is best, in aggregate, if only it was systematically randomised, and the outcomes followed up. You will hear much more on this when we discuss the need for bigger, simpler trials in the next chapter, because this problem is not academic: lives are lost through our uncritical acceptance of trials that fail to measure real-world outcomes.
Trials that bundle their outcomes together in odd ways
Sometimes, the way you package up your outcome data can give misleading results. For example, by setting your thresholds just right, you can turn a modest benefit into an apparently dramatic one. And by bundling up lots of different outcomes, to make one big ‘composite outcome’, you can dilute harms; or allow freak results on uninteresting outcomes to make it look as if a whole group of outcomes are improved.
Even if you collect entirely legitimate outcome data, the way you pool these outcomes together over the course of a trial can be misleading. There are some simple examples of this, and then some slightly more complicated ones.
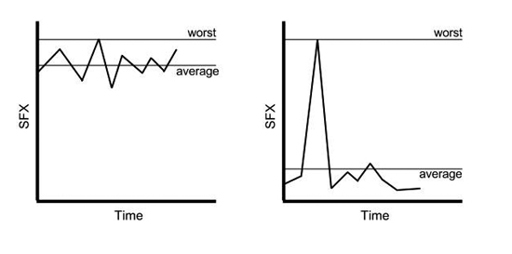
As a very crude example, many papers (mercifully, mostly, in the past) have used the ‘worst-ever side-effects score’ method.
19
This can be very misleading, as it takes the worst side effects a patient has ever scored during a trial, rather than a sum of all their side-effects scores throughout its whole duration. In the graphs below, you can see why this poses such a problem, because the drug on the left is made to look as good as the drug on the right, by using this ‘worst-ever side-effects score’ method, even though the drug on the right is clearly better for side effects.
Another misleading summary can be created by choosing a cut-off for success, and pretending that this indicates a meaningful treatment benefit, where in reality there has been no such thing. For example, a 10 per cent reduction in symptom severity may be defined as success in a trial, even though it still leaves patients profoundly disabled.
20
This is particularly misleading if one treatment achieves a dramatic benefit if it works at all, and another a modest benefit if it works at all, but both get over the arbitrary and modest 10 per cent benefit threshold in the same number of patients: suddenly, a very inferior drug has been made to look just as good as the best in its class.
You can also mix lots of different outcomes together to produce one ‘composite outcome’.
21
Often this is legitimate, but sometimes it can overstate benefits. For example, heart attacks are a fairly rare event in life generally, and also in most trials of cardiovascular drugs, which is why such trials often have to be very large, in order to have a chance of detecting a difference in the rate of heart attacks between the two groups. Because of this, it’s fairly common to see ‘important cardiovascular endpoints’ all bundled up together. This ‘composite outcome’ will include death, heart attack and angina (angina, in case you don’t know, is chest pain caused by heart problems: it’s a worry, but not as much of a worry as heart attack and death). A massive improvement in that omnibus score can feel like a huge breakthrough for heart attack and death, until you look closely at the raw data, and see that there were hardly any heart attacks or deaths in the duration of the study at all, and all you’re really seeing is some improvement in angina.
One particularly influential composite outcome came from a famous British trial called UKPDS, which looked to see whether intensively managing the blood-sugar levels of patients with diabetes made a difference to their real-world outcomes. This reported three endpoints: it found no benefit for the first two, which were death and diabetes-related death; but it did report a 12 per cent reduction in the composite outcome. This composite outcome consisted of lots of things:
- sudden death
- death from high or low blood sugar
- fatal heart attack
- non-fatal heart attack
- angina
- heart failure
- stroke
- renal failure
- amputation
- bleeding into the middle chamber of the eye
- diabetes-related damage to the arteries in the eye requiring laser treatment
- blindness in one eye
- cataracts requiring extraction
That’s quite a list, and a 12 per cent reduction on all of it bundled up together certainly feels like ‘patient oriented evidence that matters’, as we say in the business (‘POEMs’ if you prefer). But most of the improvement in this composite outcome was caused by a reduction in the number of people referred for laser treatment for damage to the arteries in their eyes. That’s nice, but it’s hardly the most important thing on that list, and it’s very much a process outcome, rather than a concrete, real-world one. If you’re interested in real-world outcomes, there wasn’t even any change in the number of people experiencing visual loss, but in any case, it’s clearly a much less important outcome than heart attacks, deaths, strokes or amputation. Similarly, the trial found a benefit for some blood markers suggestive of kidney problems, but no change in actual end-stage kidney disease.
This is only interesting because UKPDS has a slightly legendary status, among medics, as showing the benefit, on multiple outcomes, from intensive blood-sugar control for people with diabetes. How was this widespread belief created? One enterprising group of researchers decided to find every one of the thirty-five diabetes review papers citing the UKPDS study, and see what they said about it.
22
Twenty-eight said that the trial found a benefit for the composite outcome, but only one mentioned that most of this was down to improvements on the most trivial outcomes, and only six that it found no benefit for death, which is surely the ultimate outcome that matters. There is a terrifying reality revealed by this study: rumours, oversimplifications and wishful thinking can spread through the academic literature, just as easily as they do through any internet discussion forum.
Trials that ignore drop-outs
Sometimes patients leave a trial altogether, often because they didn’t like the drug they were on. But when you analyse the two groups in your trial you have to make sure you analyse all the patients assigned to a treatment. Otherwise you overstate the benefits of your drug.