Superintelligence: Paths, Dangers, Strategies (59 page)
Read Superintelligence: Paths, Dangers, Strategies Online
Authors: Nick Bostrom
Tags: #Science, #Philosophy, #Non-Fiction

11
. One might wonder why it appears
we humans
are not trying to disable the mechanism that leads us to acquire new final values. Several factors might be at play. First, the human motivation system is poorly described as a coldly calculating utility-maximizing algorithm. Second, we might not have any convenient means of altering the ways we acquire values. Third, we may have instrumental reasons (arising, e.g., from social signaling needs) for sometimes acquiring new final values—instrumental values might not be as useful if our minds are partially transparent to other people, or if the cognitive complexity of pretending to have a different set of final values than we actually do is too taxing. Fourth, there are cases where we
do
actively resist tendencies that produce changes in our final values, for instance when we seek to resist the corrupting influence of bad company. Fifth, there is the interesting possibility that we place some final value on being the kind of agent that can acquire new final values in normal human ways.
12
. Or one might try to design the motivation system so that the AI is indifferent to such replacement; see Armstrong (2010).
13
. We will here draw on some elucidations made by Daniel Dewey (2011). Other background ideas contributing to this framework have been developed by Marcus Hutter (2005) and Shane Legg (2008), Eliezer Yudkowsky (2001), Nick Hay (2005), Moshe Looks, and Peter de Blanc.
14
. To avoid unnecessary complications, we confine our attention to deterministic agents that do not discount future rewards.
15
. Mathematically, an agent’s behavior can be formalized as an
agent function
, which maps each possible interaction history to an action. Except for the very simplest agents, it is infeasible to represent the agent function explicitly as a lookup table. Instead, the agent is given some way of computing which action to perform. Since there are many ways of computing the same agent function, this leads to a finer individuation of an agent as an
agent program
. An agent program is a specific program or algorithm that computes an action for any given interaction history. While it is often mathematically convenient and useful to think of an agent program that interacts with some formally specified environment, it is important to remember that this is an idealization. Real agents are physically instantiated. This means not only that the agent interacts with the environment via its sensors and effectors, but also that the agent’s “brain” or controller
is itself part of physical reality
. Its operations can therefore in principle be affected by external physical interferences (and not only by receiving percepts from its sensors). At some point, therefore, it becomes necessary to view an agent as an
agent implementation
. An agent implementation is a physical structure that, in the absence of interference from its environment, implements an agent function. (This definition follows Dewey [2011].)
16
. Dewey proposes the following optimality notion for a value learning agent:
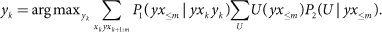
Here,
P
1
and
P
2
are two probability functions. The second summation ranges over some suitable class of utility functions over possible interaction histories. In the version presented in the text, we have made explicit some dependencies as well as availed ourselves of the simplifying possible worlds notation.
17
. It should be noted that the set of utility functionsshould be such that utilities can be compared and averaged. In general, this is problematic, and it is not always obvious how to represent
different moral theories of the good in terms of cardinal utility functions. See, e.g., MacAskill 2010).
18
. Or more generally, since ν might not be such as to directly imply for any given pair of a possible world and a utility function (
w, U
) whether the proposition ν(
U
) is true in
w
, what needs to be done is to give the AI an adequate representation of the conditional probability distribution
P
(ν(
U
) |
w
).
19
. Consider first, the class of actions that are possible for an agent. One issue here is what exactly should count as an action: only basic motor commands (e.g. “send an electric pulse along output channel #00101100”), or higher-level actions (e.g. “keep camera centered on face”)? Since we are trying to develop an optimality notion rather than a practical implementation plan, we may take the domain to be basic motor commands (and since the set of possible motor commands might change over time, we may need to index
Consider next
, which is a class of possible worlds. One difficulty here is to specify
w
in