Superintelligence: Paths, Dangers, Strategies (36 page)
Read Superintelligence: Paths, Dangers, Strategies Online
Authors: Nick Bostrom
Tags: #Science, #Philosophy, #Non-Fiction

We may consequently consider whether we might build the motivation system for an artificial intelligence on the same principle. That is, instead of specifying complex values directly, could we specify some mechanism that leads to the acquisition of those values when the AI interacts with a suitable environment?
Mimicking the value-accretion process that takes place in humans seems difficult. The relevant genetic mechanism in humans is the product of eons of work by evolution, work that might be hard to recapitulate. Moreover, the mechanism is presumably closely tailored to the human neurocognitive architecture and therefore not applicable in machine intelligences other than whole brain emulations. And if whole brain emulations of sufficient fidelity were available, it would seem easier to start with an adult brain that comes with full representations of some human values preloaded.
10
Seeking to implement a process of value accretion closely mimicking that of human biology therefore seems an unpromising line of attack on the value-loading problem. But perhaps we might design a more unabashedly artificial substitute mechanism that would lead an AI to import high-fidelity representations of relevant complex values into its goal system? For this to succeed, it may not be necessary to give the AI exactly the same evaluative dispositions as a biological human. That may not even be desirable as an aim—human nature, after all, is flawed and all too often reveals a proclivity to evil which would be intolerable in any system poised to attain a decisive strategic advantage. Better, perhaps, to aim for a motivation system that departs from the human norm in systematic ways, such as by having a more robust tendency to acquire final goals that are altruistic, compassionate, or high-minded in ways we would recognize as reflecting exceptionally good character if they were present in a human person. To count as improvements, however, such deviations from the human norm would have to be pointed in very particular directions rather than at random; and they would continue to presuppose the existence of a largely undisturbed anthropocentric frame of reference to provide humanly meaningful evaluative generalizations (so as to avoid the kind of perverse instantiation of superficially plausible goal descriptions that we examined in
Chapter 8
). It is an open question whether this is feasible.
One further issue with associative value accretion is that the AI might disable the accretion mechanism. As we saw in
Chapter 7
, goal-system integrity is a convergent instrumental value. When the AI reaches a certain stage of cognitive development it may start to regard the continued operation of the accretion mechanism as a corrupting influence.
11
This is not necessarily a bad thing, but care would have to be taken to make the sealing-up of the goal system occur at the right moment,
after
the appropriate values have been accreted but
before
they have been overwritten by additional unintended accretions.
Another approach to the value-loading problem is what we may refer to as motivational scaffolding. It involves giving the seed AI an interim goal system, with relatively simple final goals that we can represent by means of explicit coding or some other feasible method. Once the AI has developed more sophisticated representational faculties, we replace this interim scaffold goal system with one that has different final goals. This successor goal system then governs the AI as it develops into a full-blown superintelligence.
Because the scaffold goals are not just instrumental but
final
goals for the AI, the AI might be expected to resist having them replaced (goal-content integrity being a convergent instrumental value). This creates a hazard. If the AI succeeds in thwarting the replacement of its scaffold goals, the method fails.
To avoid this failure mode, precautions are necessary. For example, capability control methods could be applied to limit the AI’s powers until the mature motivation system has been installed. In particular, one could try to stunt its cognitive development at a level that is safe but that allows it to represent the values that we want to include in its ultimate goals. To do this, one might try to differentially stunt certain types of intellectual abilities, such as those required for strategizing and Machiavellian scheming, while allowing (apparently) more innocuous abilities to develop to a somewhat higher level.
One could also try to use motivation selection methods to induce a more collaborative relationship between the seed AI and the programmer team. For example, one might include in the scaffold motivation system the goal of welcoming online guidance from the programmers, including allowing them to replace any of the AI’s current goals.
12
Other scaffold goals might include being transparent to the programmers about its values and strategies, and developing an architecture that is easy for the programmers to understand and that facilitates the later implementation of a humanly meaningful final goal, as well as domesticity motivations (such as limiting the use of computational resources).
One could even imagine endowing the seed AI with the sole final goal of replacing itself with a different final goal, one which may have been only implicitly or indirectly specified by the programmers. Some of the issues raised by the use of such a “self-replacing” scaffold goal also arise in the context of the value learning approach, which is discussed in the next subsection. Some further issues will be discussed in
Chapter 13
.
The motivational scaffolding approach is not without downsides. One is that it carries the risk that the AI could become too powerful while it is still running on its interim goal system. It may then thwart the human programmers’ efforts to install the ultimate goal system (either by forceful resistance or by quiet subversion). The old final goals may then remain in charge as the seed AI develops into a full-blown superintelligence. Another downside is that installing the ultimately intended goals in a human-level AI is not necessarily that much easier than doing so in a more primitive AI. A human-level AI is more complex and might
have developed an architecture that is opaque and difficult to alter. A seed AI, by contrast, is like a
tabula rasa
on which the programmers can inscribe whatever structures they deem helpful. This downside could be flipped into an upside if one succeeded in giving the seed AI scaffold goals that made it want to develop an architecture helpful to the programmers in their later efforts to install the ultimate final values. However, it is unclear how easy it would be to give a seed AI scaffold goals with this property, and it is also unclear how even an ideally motivated seed AI would be capable of doing a much better job than the human programming team at developing a good architecture.
We come now to an important but subtle approach to the value-loading problem. It involves using the AI’s intelligence to
learn
the values we want it to pursue. To do this, we must provide a criterion for the AI that at least implicitly picks out some suitable set of values. We could then build the AI to act according to its best estimates of these implicitly defined values. It would continually refine its estimates as it learns more about the world and gradually unpacks the implications of the value-determining criterion.
In contrast to the scaffolding approach, which gives the AI an interim scaffold goal and later replaces it with a different final goal, the value learning approach retains an unchanging final goal throughout the AI’s developmental and operational phases. Learning does not change the goal. It changes only the AI’s beliefs about the goal.
The AI thus must be endowed with a criterion that it can use to determine which percepts constitute evidence in favor of some hypothesis about what the ultimate goal is, and which percepts constitute evidence against. Specifying a suitable criterion could be difficult. Part of the difficulty, however, pertains to the problem of creating artificial general intelligence in the first place, which requires a powerful learning mechanism that can discover the structure of the environment from limited sensory inputs. That problem we can set aside here. But even modulo a solution to how to create superintelligent AI, there remain the difficulties that arise specifically from the value-loading problem. With the value learning approach, these take the form of needing to define a criterion that connects perceptual bitstrings to hypotheses about values.
Before delving into the details of how value learning could be implemented, it might be helpful to illustrate the general idea with an example. Suppose we write down a description of a set of values on a piece of paper. We fold the paper and put it in a sealed envelope. We then create an agent with human-level general intelligence, and give it the following final goal: “Maximize the realization of the values described in the envelope.” What will this agent do?
The agent does not initially know what is written in the envelope. But it can form hypotheses, and it can assign those hypotheses probabilities based on their priors
and any available empirical data. For instance, the agent might have encountered other examples of human-authored texts, or it might have observed some general patterns of human behavior. This would enable it to make guesses. One does not need a degree in psychology to predict that the note is more likely to describe a value such as “minimize injustice and unnecessary suffering” or “maximize returns to shareholders” than a value such as “cover all lakes with plastic shopping bags.”
When the agent makes a decision, it seeks to take actions that would be effective at realizing the values it believes are most likely to be described in the letter. Importantly, the agent would see a high instrumental value in learning more about what the letter says. The reason is that for almost any final value that might be described in the letter, that value is more likely to be realized if the agent finds out what it is, since the agent will then pursue that value more effectively. The agent would also discover the convergent instrumental reasons described in
Chapter 7
—goal system integrity, cognitive enhancement, resource acquisition, and so forth. Yet, assuming that the agent assigns a sufficiently high probability to the values described in the letter involving human welfare, it would
not
pursue these instrumental values by immediately turning the planet into computronium and thereby exterminating the human species, because doing so would risk permanently destroying its ability to realize its final value.
We can liken this kind of agent to a barge attached to several tugboats that pull in different directions. Each tugboat corresponds to a hypothesis about the agent’s final value. The engine power of each tugboat corresponds to the associated hypothesis’s probability, and thus changes as new evidence comes in, producing adjustments in the barge’s direction of motion. The resultant force should move the barge along a trajectory that facilitates learning about the (implicit) final value while avoiding the shoals of irreversible destruction; and later, when the open sea of more definite knowledge of the final value is reached, the one tugboat that still exerts significant force will pull the barge toward the realization of the discovered value along the straightest or most propitious route.
The envelope and barge metaphors illustrate the principle underlying the value learning approach, but they pass over a number of critical technical issues. They come into clearer focus once we start to develop the approach within a formal framework (see
Box 10
).
One outstanding issue is how to endow the AI with a goal such as “Maximize the realization of the values described in the envelope.” (In the terminology of
Box 10
, how to define the value criterion.) To do this, it is necessary to identify the place where the values are described. In our example, this requires making a successful reference to the letter in the envelope. Though this might seem trivial, it is not without pitfalls. To mention just one: it is critical that the reference be not simply to a particular external physical object but to an object at a particular time. Otherwise the AI may determine that the best way to attain its goal is by overwriting the original value description with one that provides an easier target (such as the value that for every integer there be a larger integer). This done, the AI
could lean back and crack its knuckles—though more likely a malignant failure would ensue, for reasons we discussed in
Chapter 8
. So now we face the question of how to define time. We could point to a clock and say, “Time is defined by the movements of this device”—but this could fail if the AI conjectures that it can manipulate time by moving the hands on the clock, a conjecture which would indeed be correct if “time” were given the aforesaid definition. (In a realistic case, matters would be further complicated by the fact that the relevant values are not going to be conveniently described in a letter; more likely, they would have to be inferred from observations of pre-existing structures that implicitly contain the relevant information, such as human brains.)
Introducing some formal notation can help us see some things more clearly. However, readers who dislike formalism can skip this part.
Consider a simplified framework in which an agent interacts with its environment in a finite number of discrete cycles.
13
In cycle
k
, the agent performs action
y
k
, and then receives the percept
x
k
. The interaction history of an agent with lifespan
m
is a string
y
1
x
1
y
2
x
2
…
y
m
x
m
(which we can abbreviate as
yx
1:
m
or
yx
≤
m
). In each cycle, the agent selects an action based on the percept sequence it has received to date.
Consider first a reinforcement learner. An optimal reinforcement learner (AI-RL) is one that maximizes expected future rewards. It obeys the equation
14
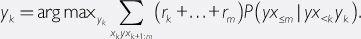
The reward sequence
r
k
, …,
r
m
is implied by the percept sequence
x
k:m
, since the reward that the agent receives in a given cycle is part of the percept that the agent receives in that cycle.
As argued earlier, this kind of reinforcement learning is unsuitable in the present context because a sufficiently intelligent agent will realize that it could secure maximum reward if it were able to directly manipulate its reward signal (wireheading). For weak agents, this need not be a problem, since we can physically prevent them from tampering with their own reward channel. We can also control their environment so that they receive rewards only when they act in ways that are agreeable to us. But a reinforcement learner has a strong incentive to eliminate this artificial dependence of its rewards on our whims and wishes. Our relationship with a reinforcement learner is therefore fundamentally antagonistic. If the agent is strong, this spells danger.
Variations of the wireheading syndrome can also affect systems that do not seek an external sensory reward signal but whose goals are defined as the attainment of some internal state. For example, in so-called “actor–critic” systems, there is an actor module that selects actions in order to minimize the disapproval of a separate critic module that computes how far the agent’s behavior falls short of a given performance measure. The problem with this setup is that the actor module may realize that it can minimize disapproval by modifying the critic or eliminating it altogether—much like a dictator who dissolves the parliament and nationalizes the press. For limited systems, the problem can be avoided simply by not giving the actor module any means of modifying the critic module. A sufficiently intelligent and resourceful actor module, however, could always gain access to the critic module (which, after all, is merely a physical process in some computer).
15
Before we get to the value learner, let us consider as an intermediary step what has been called an observation-utility maximizer (AI-OUM). It is obtained by replacing the reward series (
r
k
+ … +
r
m
) in the AI-RL with a utility function that is allowed to depend on the entire future interaction history of the AI:
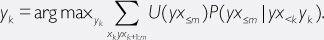
This formulation provides a way around the wireheading problem because a utility function defined over an entire interaction history could be designed to penalize interaction histories that show signs of self-deception (or of a failure on the part of the agent to invest sufficiently in obtaining an accurate view of reality).
The AI-OUM thus makes it possible
in principle
to circumvent the wireheading problem. Availing ourselves of this possibility, however, would require that we specify a suitable utility function over the class of possible interaction histories—a task that looks forbiddingly difficult.
It may be more natural to specify utility functions directly in terms of possible worlds (or properties of possible worlds, or theories about the world) rather than in terms of an agent’s own interaction histories. If we use this approach, we could reformulate and simplify the AI-OUM optimality notion:
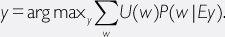
Here,
E
is the total evidence available to the agent (at the time when it is making its decision), and
U
is a utility function that assigns utility to some class of possible worlds. The optimal agent chooses the act that maximizes expected utility.
An outstanding problem with these formulations is the difficulty of defining the utility function
U
. This, finally, returns us to the value-loading problem. To enable the utility function to be learned, we must expand our formalism to allow for uncertainty over utility functions. This can be done as follows (AI-VL):
16
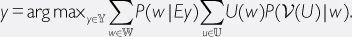
Here,
ν
(.) is a function from utility functions to propositions about utility functions.
ν
(
U
) is the proposition that the utility function
U
satisfies the
value criterion
expressed by
ν
.
17
To decide which action to perform, one could hence proceed as follows: First, compute the conditional probability of each possible world
w
(given available evidence and on the supposition that action
y
is to be performed). Second, for each possible utility function
U
, compute the conditional probability that
U
satisfies the value criterion ν (conditional on
w
being the actual world). Third, for each possible utility function
U
, compute the utility of possible world
w
. Fourth, combine these quantities to compute the expected utility of action
y
. Fifth, repeat this procedure for each possible action, and perform the action found to have the highest expected utility (using some arbitrary method to break ties). As described, this procedure—which involves giving explicit and separate consideration to each possible world—is, of course, wildly computationally intractable. The AI would have to use computational shortcuts that approximate this optimality notion.
The question, then, is how to define this value criterion
ν
.
18
Once the AI has an adequate representation of the value criterion, it could in principle use its general intelligence to gather information about which possible worlds are most likely to be the actual one. It could then apply the criterion, for each such plausible possible world
w
, to find out which utility function satisfies the criterion in
w
. One can thus regard the AI-VL formula as a way of identifying and separating out this key challenge in the value learning approach—the challenge of how to represent
ν
. The formalism also brings to light a number of other issues (such as how to define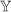 ,
, , and
, and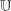 ) which would need to be resolved before the approach could be made to work.
) which would need to be resolved before the approach could be made to work.
19