Superintelligence: Paths, Dangers, Strategies (16 page)
Read Superintelligence: Paths, Dangers, Strategies Online
Authors: Nick Bostrom
Tags: #Science, #Philosophy, #Non-Fiction

Figure 8
A less anthropomorphic scale? The gap between a dumb and a clever person may appear large from an anthropocentric perspective, yet in a less parochial view the two have nearly indistinguishable minds.
9
It will almost certainly prove harder and take longer to build a machine intelligence that has a general level of smartness comparable to that of a village idiot than to improve such a system so that it becomes much smarter than any human.
Consider a contemporary AI system such as TextRunner (a research project at the University of Washington) or IBM’s Watson (the system that won the
Jeopardy!
quiz show). These systems can extract certain pieces of semantic information by analyzing text. Although these systems do not understand what they read in the same sense or to the same extent as a human does, they can nevertheless extract significant amounts of information from natural language and use that information to make simple inferences and answer questions. They can also learn from experience, building up more extensive representations of a concept as they encounter additional instances of its use. They are designed to operate for much of the time in unsupervised mode (i.e. to learn hidden structure in unlabeled data in the absence of error or reward signal, without human guidance) and to be fast and scalable. TextRunner, for instance, works with a corpus of 500 million web pages.
10
Now imagine a remote descendant of such a system that has acquired the ability to read with as much understanding as a human ten-year-old but with a reading speed similar to that of TextRunner. (This is probably an AI-complete problem.) So we are imagining a system that thinks much faster and has much better memory than a human adult, but knows much less, and perhaps the net effect of this is that the system is roughly human-equivalent in its general problem-solving ability. But its content recalcitrance is very low—low enough to precipitate a takeoff. Within a few weeks, the system has read and mastered all the content contained in the Library of Congress. Now the system knows much more than any human being and thinks vastly faster: it has become (at least) weakly superintelligent.
A system might thus greatly boost its effective intellectual capability by absorbing pre-produced content accumulated through centuries of human science and civilization: for instance, by reading through the Internet. If an AI reaches human level without previously having had access to this material or without having been able to digest it, then the AI’s overall recalcitrance will be low even if it is hard to improve its algorithmic architecture.
Content-recalcitrance is a relevant concept for emulations, too. A high-speed emulation has an advantage not only because it can complete the same tasks as biological humans more quickly, but also because it can accumulate more timely content, such as task-relevant skills and expertise. In order to tap the full potential of fast content accumulation, however, a system needs to have a correspondingly large memory capacity. There is little point in reading an entire library if you have forgotten all about the aardvark by the time you get to the abalone. While an AI system is likely to have adequate memory capacity, emulations
would inherit some of the capacity limitations of their human templates. They may therefore need architectural enhancements in order to become capable of unbounded learning.
So far we have considered the recalcitrance of architecture and of content—that is, how difficult it would be to improve the
software
of a machine intelligence that has reached human parity. Now let us look at a third way of boosting the performance of machine intelligence: improving its hardware. What would be the recalcitrance for hardware-driven improvements?
Starting with intelligent software (emulation or AI) one can amplify
collective intelligence
simply by using additional computers to run more instances of the program.
11
One could also amplify
speed intelligence
by moving the program to faster computers. Depending on the degree to which the program lends itself to parallelization, speed intelligence could also be amplified by running the program on more processors. This is likely to be feasible for emulations, which have a highly parallelized architecture; but many AI programs, too, have important subroutines that can benefit from massive parallelization. Amplifying
quality intelligence
by increasing computing power might also be possible, but that case is less straightforward.
12
The recalcitrance for amplifying collective or speed intelligence (and possibly quality intelligence) in a system with human-level software is therefore likely to be low. The only difficulty involved is gaining access to additional computing power. There are several ways for a system to expand its hardware base, each relevant over a different timescale.
In the short term, computing power should scale roughly linearly with funding: twice the funding buys twice the number of computers, enabling twice as many instances of the software to be run simultaneously. The emergence of cloud computing services gives a project the option to scale up its computational resources without even having to wait for new computers to be delivered and installed, though concerns over secrecy might favor the use of in-house computers. (In certain scenarios, computing power could also be obtained by other means, such as by commandeering botnets.
13
) Just how easy it would be to scale the system by a given factor depends on how much computing power the initial system uses. A system that initially runs on a PC could be scaled by a factor of thousands for a mere million dollars. A program that runs on a supercomputer would be far more expensive to scale.
In the slightly longer term, the cost of acquiring additional hardware may be driven up as a growing portion of the world’s installed capacity is being used to run digital minds. For instance, in a competitive market-based emulation scenario, the cost of running one additional copy of an emulation should rise to be roughly equal to the income generated by the marginal copy, as investors bid up the price for existing computing infrastructure to match the return they expect from their investment (though if only one project has mastered the technology it might gain a degree of monopsony power in the computing power market and therefore pay a lower price).
Over a somewhat longer timescale, the supply of computing power will grow as new capacity is installed. A demand spike would spur production in existing semiconductor foundries and stimulate the construction of new plants. (A one-off performance boost, perhaps amounting to one or two orders of magnitude, might also be obtainable by using customized microprocessors.
14
) Above all, the rising wave of technology improvements will pour increasing volumes of computational power into the turbines of the thinking machines. Historically, the rate of improvement of computing technology has been described by the famous Moore’s law, which in one of its variations states that computing power per dollar doubles every 18 months or so.
15
Although one cannot bank on this rate of improvement continuing up to the development of human-level machine intelligence, yet until fundamental physical limits are reached there will remain room for advances in computing technology.
There are thus reasons to expect that hardware recalcitrance will not be very high. Purchasing more computing power for the system once it proves its mettle by attaining human-level intelligence might easily add several orders of magnitude of computing power (depending on how hardware-frugal the project was before expansion). Chip customization might add one or two orders of magnitude. Other means of expanding the hardware base, such as building more factories and advancing the frontier of computing technology, take longer—normally several years, though this lag would be radically compressed once machine superintelligence revolutionizes manufacturing and technology development.
In summary, we can talk about the likelihood of a
hardware overhang
: when human-level software is created, enough computing power may already be available to run vast numbers of copies at great speed. Software recalcitrance, as discussed above, is harder to assess but might be even lower than hardware recalcitrance. In particular, there may be
content overhang
in the form of pre-made content (e.g. the Internet) that becomes available to a system once it reaches human parity.
Algorithm overhang
—pre-designed algorithmic enhancements—is also possible but perhaps less likely. Software improvements (whether in algorithms or content) might offer orders of magnitude of potential performance gains that could be fairly easily accessed once a digital mind attains human parity, on top of the performance gains attainable by using more or better hardware.
Having examined the question of recalcitrance we must now turn to the other half of our schematic equation,
optimization power
. To recall:
Rate of change in Intelligence = Optimization power/Recalcitrance
. As reflected in this schematic, a fast takeoff does not require that recalcitrance during the transition phase be low. A fast takeoff could also result if recalcitrance is constant or even moderately increasing, provided the optimization power being applied to improving the system’s performance grows sufficiently rapidly. As we shall now see, there are good
grounds for thinking that the applied optimization power
will
increase during the transition, at least in the absence of a deliberate measures to prevent this from happening.
We can distinguish two phases. The first phase begins with the onset of the takeoff, when the system reaches the human baseline for individual intelligence. As the system’s capability continues to increase, it might use some or all of that capability to improve itself (or to design a successor system—which, for present purposes, comes to the same thing). However, most of the optimization power applied to the system still comes from outside the system, either from the work of programmers and engineers employed within the project or from such work done by the rest of the world as can be appropriated and used by the project.
16
If this phase drags out for any significant period of time, we can expect the amount of optimization power applied to the system to grow. Inputs both from inside the project and from the outside world are likely to increase as the promise of the chosen approach becomes manifest. Researchers may work harder, more researchers may be recruited, and more computing power may be purchased to expedite progress. The increase could be especially dramatic if the development of human-level machine intelligence takes the world by surprise, in which case what was previously a small research project might suddenly become the focus of intense research and development efforts around the world (though some of those efforts might be channeled into competing projects).
A second growth phase will begin if at some point the system has acquired so much capability that most of the optimization power exerted on it comes from the system itself (marked by the variable level labeled “crossover” in
Figure 7
). This fundamentally changes the dynamic, because any increase in the system’s capability now translates into a proportional increase in the amount of optimization power being applied to its further improvement. If recalcitrance remains constant, this feedback dynamic produces exponential growth (see
Box 4
). The doubling constant depends on the scenario but might be extremely short—mere seconds in some scenarios—if growth is occurring at electronic speeds, which might happen as a result of algorithmic improvements or the exploitation of an overhang of content or hardware.
17
Growth that is driven by physical construction, such as the production of new computers or manufacturing equipment, would require a somewhat longer timescale (but still one that might be very short compared with the current growth rate of the world economy).
It is thus likely that the applied optimization power will increase during the transition: initially because humans try harder to improve a machine intelligence that is showing spectacular promise, later because the machine intelligence itself becomes capable of driving further progress at digital speeds. This would create a real possibility of a fast or medium takeoff
even if recalcitrance were constant or slightly increasing around the human baseline
.
18
Yet we saw in the previous subsection that there are factors that could lead to a big drop in recalcitrance around the human baseline level of capability. These factors include, for example, the possibility of rapid hardware expansion once a working software mind has been attained; the possibility of algorithmic improvements; the possibility of scanning additional brains (in the case of whole brain emulation); and the possibility of rapidly incorporating vast amounts of content by digesting the Internet (in the case of artificial intelligence).
24
We can write the rate of change in intelligence as the ratio between the optimization power applied to the system and the system’s recalcitrance:
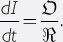
The amount of optimization power acting on a system is the sum of whatever optimization power the system itself contributes and the optimization power exerted from without. For example, a seed AI might be improved through a combination of its own efforts and the efforts of a human programming team, and perhaps also the efforts of the wider global community of researchers making continuous advances in the semiconductor industry, computer science, and related fields:
19
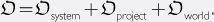
A seed AI starts out with very limited cognitive capacities. At the outset, therefore, is small.
is small.
20
What about and
and ? There are cases in which a single project has more relevant capability than the rest of the world combined—the Manhattan project, for instance, brought a very large fraction of the world’s best physicists to Los Alamos to work on the atomic bomb. More commonly, any one project contains only a small fraction of the world’s total relevant research capability. But even when the outside world has a greater total amount of relevant research capability than any one project,may nevertheless exceed, since much of the outside world’s capability is not be focused on the particular system in question. If a project begins to look promising—which will happen when a system passes the human baseline if not before—it might attract additional investment, increasing. If the project’s accomplishments are public,might also rise as the progress inspires greater interest in machine intelligence generally and as various powers scramble to get in on the game. During the transition phase, therefore, total optimization power applied to improving a cognitive system is likely to increase as the capability of the system increases.
? There are cases in which a single project has more relevant capability than the rest of the world combined—the Manhattan project, for instance, brought a very large fraction of the world’s best physicists to Los Alamos to work on the atomic bomb. More commonly, any one project contains only a small fraction of the world’s total relevant research capability. But even when the outside world has a greater total amount of relevant research capability than any one project,may nevertheless exceed, since much of the outside world’s capability is not be focused on the particular system in question. If a project begins to look promising—which will happen when a system passes the human baseline if not before—it might attract additional investment, increasing. If the project’s accomplishments are public,might also rise as the progress inspires greater interest in machine intelligence generally and as various powers scramble to get in on the game. During the transition phase, therefore, total optimization power applied to improving a cognitive system is likely to increase as the capability of the system increases.
21
As the system’s capabilities grow, there may come a point at which the optimization power generated by the system itself starts to dominate the optimization power applied to it from outside (across all significant dimensions of improvement):
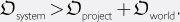
This
crossover
is significant because beyond this point, further improvement to the system’s capabilities contributes strongly to increasing the total optimization power applied to improving the system. We thereby enter a regime
of strong recursive self-improvement. This leads to explosive growth of the system’s capability under a fairly wide range of different shapes of the recalcitrance curve.
To illustrate, consider first a scenario in which recalcitrance is constant, so that the rate of increase in an AI’s intelligence is equal to the optimization power being applied. Assume that all the optimization power that is applied comes from the AI itself and that the AI applies all its intelligence to the task of amplifying its own intelligence, so that=
I
.
22
We then have